
on my way
[프로그래머스 코딩테스트 연습 SQL] 즐겨찾기가 가장 많은 식당 정보 출력하기 (MySQL) | RANK() 함수 본문
[프로그래머스 코딩테스트 연습 SQL] 즐겨찾기가 가장 많은 식당 정보 출력하기 (MySQL) | RANK() 함수
wingbeat 2024. 8. 4. 05:37
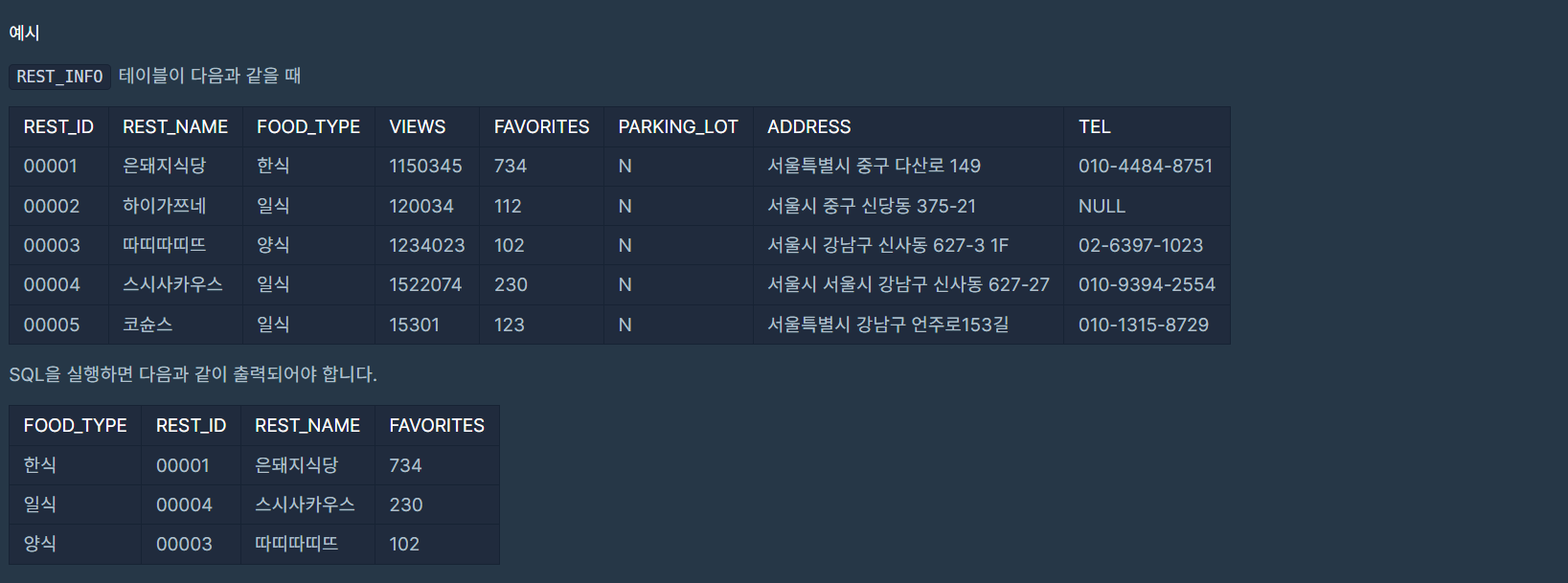
문제 설명
이 문제는 REST_INFO 테이블에서 음식 종류별로 즐겨찾기 수가 가장 많은 식당의 정보를 조회하는 것이다.
결과는 음식 종류를 기준으로 내림차순 정렬되어야 한다.
문제 풀이
내가 틀린 코드
SELECT *
FROM (SELECT FOOD_TYPE, REST_ID, REST_NAME, MAX(FAVORITES) AS FAVORITES
FROM REST_INFO
GROUP BY FOOD_TYPE ) R
ORDER BY FOOD_TYPE DESC이 코드가 틀린 이유는 GROUP BY 절에서 FOOD_TYPE만 그룹화 했기 때문에 REST_ID와 REST_NAME의 값이 정확히 어떤 값인지 알 수 없기 때문이다.
MAX(FAVORITES)는 FOOD_TYPE 그룹 내에서 가장 큰 즐겨찾기 수를 의미하지만, 그 값이 어느 식당의 REST_ID와 REST_NAME인지 정확히 매칭되지 않는다.
정답 코드
SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
FROM REST_INFO
WHERE (FOOD_TYPE, FAVORITES) IN (
SELECT FOOD_TYPE, MAX(FAVORITES)
FROM REST_INFO
GROUP BY FOOD_TYPE
)
ORDER BY FOOD_TYPE DESC;이 정답 코드는 내부 서브쿼리를 통해 각 음식 종류별로 가장 많은 즐겨찾기 수를 가진 식당을 찾아낸다.
서브쿼리: SELECT FOOD_TYPE, MAX(FAVORITES) FROM REST_INFO GROUP BY FOOD_TYPE
각 음식 종류별로 MAX(FAVORITES)를 구한다.
이 쿼리는 음식 종류별로 가장 많은 즐겨찾기 수를 구한다.
메인쿼리: SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES FROM REST_INFO WHERE (FOOD_TYPE, FAVORITES) IN ( SELECT FOOD_TYPE, MAX(FAVORITES) FROM REST_INFO GROUP BY FOOD_TYPE ) ORDER BY FOOD_TYPE DESC;
WHERE (FOOD_TYPE, FAVORITES) IN 절을 사용하여, 서브쿼리에서 구한 음식 종류와 즐겨찾기 수를 가진 식당 정보를 필터링한다.
여기서 (FOOD_TYPE, FAVORITES)가 서브쿼리의 결과와 일치하는 행만 선택된다.
이때, FOOD_TYPE를 기준으로 내림차순으로 정렬한다.
따라서, 최종 결과는 음식 종류별로 즐겨찾기 수가 가장 많은 식당의 정보를 조회할 수 있다.
현재 쿼리는 FOOD_TYPE과 FAVORITES를 기준으로 필터링하고 있기 때문에, 같은 FOOD_TYPE과 같은 FAVORITES 수를 가진 식당이 여러 개 있을 경우 모두 출력된다. 이를 해결하기 위해서는 REST_ID까지 고려해야 한다.
이를 위해 ROW_NUMBER() 윈도우 함수를 사용하여 각 FOOD_TYPE 그룹 내에서 FAVORITES 수가 가장 높은 식당을 1순위로 선택할 수 있다.
개선된 쿼리
WITH RankedRest AS (
SELECT
FOOD_TYPE, REST_ID, REST_NAME, FAVORITES,
ROW_NUMBER() OVER (PARTITION BY FOOD_TYPE ORDER BY FAVORITES DESC, REST_ID) AS rnk
FROM REST_INFO
)
SELECT
FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
FROM RankedRest
WHERE rnk = 1
ORDER BY FOOD_TYPE DESC;단계적 설명
- 윈도우 함수 사용:이 쿼리는
ROW_NUMBER()윈도우 함수를 사용하여 각FOOD_TYPE그룹 내에서FAVORITES수를 기준으로 내림차순 정렬하고, 같은FAVORITES수가 있을 경우REST_ID를 기준으로 정렬하여 순위를 매긴다.rnk열은 각 그룹 내에서 순위를 나타낸다. SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES, ROW_NUMBER() OVER (PARTITION BY FOOD_TYPE ORDER BY FAVORITES DESC, REST_ID) AS rnk FROM REST_INFO- 최고 순위 필터링:이 쿼리는
rnk가 1인 행만 선택하여 각FOOD_TYPE그룹 내에서FAVORITES수가 가장 높은 식당만을 선택한다. SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES FROM RankedRest WHERE rnk = 1 ORDER BY FOOD_TYPE DESC;
이렇게 하면 같은 FOOD_TYPE과 같은 FAVORITES 수를 가진 여러 식당이 있을 경우에도 중복되지 않고, REST_ID가 가장 낮은 하나의 식당만 선택된다
RANK() 함수는 SQL에서 순위를 매길 때 사용되는 윈도우 함수 중 하나였다. 이 함수는 특정 조건에 따라 결과 집합 내의 행들에 순위를 부여하며, 동일한 값에 대해서는 동일한 순위를 부여하는 특징이 있었다. 즉, 같은 값을 가진 행들이 동일한 순위를 공유하게 되었다.
RANK() 함수의 특징
- 동일한 값을 가진 행들은 동일한 순위를 가졌다.
- 동일한 순위가 부여된 다음 행에는 그만큼의 순위가 건너뛰었다.
예제
다음은 EMPLOYEES 테이블을 기준으로 SALARY 열을 기준으로 순위를 매기는 예제였다.
EMPLOYEES 테이블
| EMPLOYEE_ID | NAME | SALARY |
|---|---|---|
| 1 | John | 5000 |
| 2 | Jane | 6000 |
| 3 | Jack | 6000 |
| 4 | Jill | 4500 |
| 5 | Jerry | 5000 |
RANK() 함수 사용 예제
SELECT
EMPLOYEE_ID,
NAME,
SALARY,
RANK() OVER (ORDER BY SALARY DESC) AS rnk
FROM
EMPLOYEES;결과
| EMPLOYEE_ID | NAME | SALARY | rnk |
|---|---|---|---|
| 2 | Jane | 6000 | 1 |
| 3 | Jack | 6000 | 1 |
| 1 | John | 5000 | 3 |
| 5 | Jerry | 5000 | 3 |
| 4 | Jill | 4500 | 5 |
설명
Jane과Jack은 같은SALARY를 가지고 있어서 동일한 순위인1을 가졌다.- 그 다음 순위는
3으로 건너뛰며,John과Jerry도 같은SALARY를 가지므로 동일한 순위3을 가졌다. - 마지막으로
Jill은5번째 순위를 가졌다.
RANK()와 DENSE_RANK()의 차이
RANK()와 비슷한 함수로 DENSE_RANK()가 있었다. 두 함수의 차이점은 건너뛰는 순위의 존재 여부였다.
DENSE_RANK() 사용 예제
SELECT
EMPLOYEE_ID,
NAME,
SALARY,
DENSE_RANK() OVER (ORDER BY SALARY DESC) AS dense_rnk
FROM
EMPLOYEES;결과
| EMPLOYEE_ID | NAME | SALARY | dense_rnk |
|---|---|---|---|
| 2 | Jane | 6000 | 1 |
| 3 | Jack | 6000 | 1 |
| 1 | John | 5000 | 2 |
| 5 | Jerry | 5000 | 2 |
| 4 | Jill | 4500 | 3 |
DENSE_RANK()는 순위를 건너뛰지 않기 때문에 동일한 순위 이후의 순위는 연속적으로 매겨졌다. 예를 들어, RANK() 함수에서는 1, 1, 3, 3, 5였지만, DENSE_RANK() 함수에서는 1, 1, 2, 2, 3으로 매겨졌다.
ROW_NUMBER() 함수는 SQL에서 순서 번호를 부여하는 윈도우 함수였다. 이 함수는 결과 집합의 각 행에 대해 고유한 순서 번호를 부여했다. 순서 번호는 지정된 기준에 따라 정렬된 순서대로 증가했다.
ROW_NUMBER() 함수의 특징
- 동일한 값에 대해 순서 번호는 고유하게 부여되었다.
- 순서 번호는 중복되지 않고 연속적으로 증가했다.
예제
다음은 EMPLOYEES 테이블을 기준으로 SALARY 열을 기준으로 순서 번호를 매기는 예제였다.
EMPLOYEES 테이블
| EMPLOYEE_ID | NAME | SALARY |
|---|---|---|
| 1 | John | 5000 |
| 2 | Jane | 6000 |
| 3 | Jack | 6000 |
| 4 | Jill | 4500 |
| 5 | Jerry | 5000 |
ROW_NUMBER() 함수 사용 예제
SELECT
EMPLOYEE_ID,
NAME,
SALARY,
ROW_NUMBER() OVER (ORDER BY SALARY DESC) AS row_num
FROM
EMPLOYEES;결과
| EMPLOYEE_ID | NAME | SALARY | row_num |
|---|---|---|---|
| 2 | Jane | 6000 | 1 |
| 3 | Jack | 6000 | 2 |
| 1 | John | 5000 | 3 |
| 5 | Jerry | 5000 | 4 |
| 4 | Jill | 4500 | 5 |
설명
Jane과Jack은 같은SALARY를 가졌지만,ROW_NUMBER()함수는 고유한 순서 번호를 부여했다.- 순서 번호는
1부터 시작해서5까지 연속적으로 증가했다.
결론
ROW_NUMBER() 함수는 결과 집합 내의 각 행에 대해 고유한 순서 번호를 부여했다.
이는 동일한 값이 존재하더라도 고유한 순서 번호를 보장하며, 연속적으로 증가하는 특징을 가졌다.
RANK() 함수는 특정 열을 기준으로 순위를 매기되, 동일한 값에 대해 동일한 순위를 부여하며, 그 다음 순위는 건너뛰는 방식을 사용했다.
DENSE_RANK() 함수는 순위를 건너뛰지 않고 연속적으로 부여했다.
이를 통해 데이터를 순서대로 나열하거나, 특정 순서에 따라 행을 구분하는 데 유용하게 사용되었다.
'algorithm > SQL' 카테고리의 다른 글
| [프로그래머스 코딩테스트 연습 SQL] 특정한 조건을 만족하는 물고기별 수와 최대 길이 구하기 (MySQL) | COALESCE (1) | 2024.09.16 |
|---|---|
| [프로그래머스 코딩테스트 연습 SQL] 업그레이드 된 아이템 구하기 (MySQL) (0) | 2024.08.04 |
| [프로그래머스 코딩테스트 연습 SQL - 14] 조건에 맞는 개발자 찾기 (MySQL) | SQL BIT 연산 (0) | 2024.08.04 |
| [프로그래머스 코딩테스트 연습 SQL - 13] 노선별 평균 역 사이 거리 조회하기 (MySQL) (0) | 2024.08.04 |
| [프로그래머스 코딩테스트 연습 SQL - 12] 조건별로 분류하여 주문상태 출력하기 (MySQL) (0) | 2024.07.16 |



