
on my way
[코딩테스트 합격자 되기 - 2주차] 배열 (프로그래머스 문제 풀이) 본문
05. 배열
05-1. 배열 개념
배열은 인덱스와 값을 일대일 대응해 관리하는 자료구조입니다.
데이터를 저장할 수 있는 모든 공간은 인덱스와 일대일 대응하므로 어떤 위치에 있는 데이터든 한 번에 접근할 수 있습니다.
배열 선언
# 일반적인 방법
arr = [0, 0, 0, 0, 0, 0]
arr = [0] * 6
# 리스트 생성자 사용
arr = list(range(6)) # [0, 1, 2, 3, 4, 5]
# 리스트 comprehension 사용
arr = [0 for _ in range(6)] # [0, 0, 0, 0, 0, 0]
선언한 배열은 위 사진처럼 저장된다.
파이썬의 리스트는 동적으로 크기를 조절할 수 있도록 구현되어 있습니다. 파
이썬의 리스트는 다른 언어의 배열 기능을 그대로 사용할 수 있으면서 배열 크기도 가변적이므로 코딩 테스트에서 고려할 사항을 조금 더 줄여줍니다.
배열과 차원
배열이 다차원이더라도 실제로는 1차원 공간에 저장함. 즉, 배열은 차원과 무관하게 메모리에 연속 할당된다.
1차원 배열
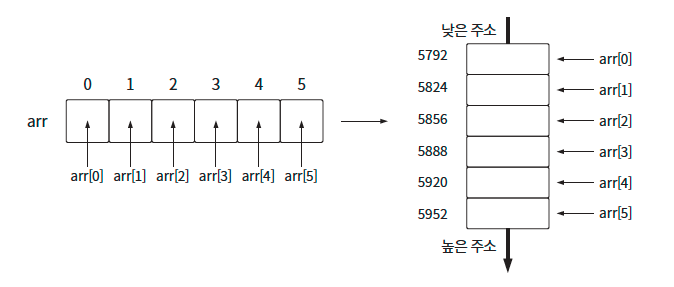
배열의 각 데이터는 메모리의 낮은 주소에서 높은 주소 방향으로 연이어 할당됩니다.
2차원 배열
1차원 배열을 확장한 것
# 2차원 배열을 리스트로 표현
arr = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
# arr[2][3]에 저장된 값을 출력
print(arr[2][3]) # 12
# arr[2][3]에 저장된 값을 15로 변경
arr[2][3] = 15
# 변경된 값을 출력
print(arr[2][3]) # 15
# List Comprehension을 활용해서 크기가 3 * 4인 리스트를 선언
arr = [[i]*4 for i in range(3)] # [[0, 0, 0, 0], [1, 1, 1, 1], [2, 2, 2, 2]]
# 2차원 배열 데이터에 접근. 행과 열을 명시해 [] 연산자를 이어 사용
arr = [[1, 2, 3], [4, 5, 6]] # ➊ 2행 3열 2차원 배열을 표현하는 리스트 선언
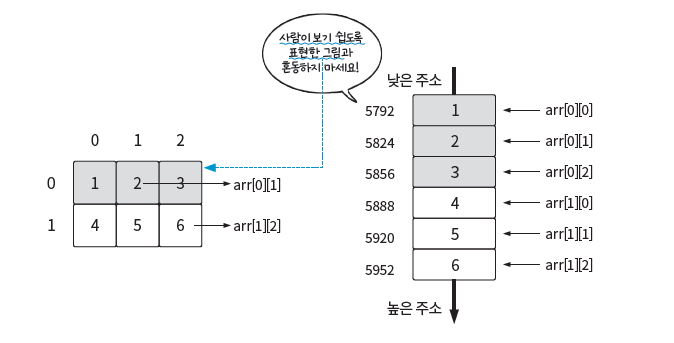
실제로는 1차원 공간에 저장된다.
05-2. 배열의 효율성
배열 연산의 시간 복잡도
배열은 임의 접근이라는 방법으로 모든 데이터에 한번에 접근할 수 있으므로 O(1)
데이터를 추가 또는 삭제할 경우에는 어디에 저장하느냐에 따라 시간 복잡도가 달라진다.
맨 뒤에 삽입
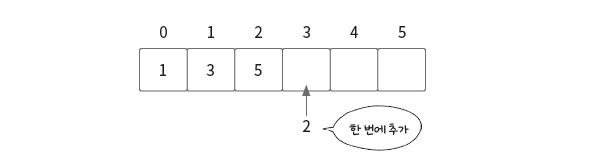
맨 뒤에 삽입할 때는 임의 접근을 바로 할 수 있으며, 데이터를 삽입해도 다른 데이터 위치에 영향을 주지 않습니다.
따라서 시간 복잡도는 O(1)입니다.
맨 앞에 삽입

이 경우 기존 데이터들을 뒤로 한 칸씩 밀어야 합니다. 즉, 미는 연산이 필요하다.
데이터 개수를 N개로 일반화하면 시간 복잡도는 O(N)
중간에 삽입

5 앞에 데이터를 삽입한다면 5 이후의 데이터를 뒤로 한 칸씩 밀어야 한다.
다시 말해 현재 삽입한 데이터 뒤에 있는 데이터 개수만큼 미는 연산을 해야 한다.
밀어야 하는 데이터 개수가 N개라면 시간 복잡도는 O(N)
배열을 선택할 때 고려해야 할 점
데이터에 자주 접근하거나 읽어야 하는 경우 배열을 사용하면 좋은 성능을 낼 수 있다.
예를 들어 그래프를 표현할 때 배열을 활용하면 임의 접근을 할 수 있으므로 간선 여부도 시간 복잡도 O(1)로 판단할 수 있다.
하지만 배열은 메모리 공간을 충분히 확보해야 하는 단점도 있습니다.
다시 말해 배열은 임의 접근이라는 특징이 있어 데이터에 인덱스로 바로 접근할 수 있어 데이터에 빈번하게 접근하는 경우 효율적이지만, 메모리 낭비가 발생할 수 있다.
따라서 코딩 테스트에서는 다음 사항을 고려해 배열을 선택해야 합니다.
01 할당할 수 있는 메모리 크기를 확인해야 합니다. 배열로 표현하려는 데이터가 너무 많으면 런타임에서 배열 할당에 실패할 수 있습니다. 운영체제마다 배열을 할당할 수 있는 메모리의 한계치는 다르지만 보통은 정수형 1차원 배열은 1000만 개, 2차원 배열은 3000 * 3000 크기를 최대로 생각합니다.
02 중간에 데이터 삽입이 많은지 확인해야 합니다. 배열은 선형 자료구조이기 때문에 중간이나 처음에 데이터를 빈번하게 삽입하면 시간 복잡도가 높아져 실제 시험에서 시간 초과가 발생할 수 있습니다.
05-3. 자주 활용하는 리스트 기법
데이터 추가
# append() 메서드로 리스트의 맨 끝에 데이터 추가
my_list = [1, 2, 3]
my_list.append(4) # [1, 2, 3, 4]
# + 연산자로 데이터 추가
my_list = [1, 2, 3]
my_list = my_list + [4, 5] # [1, 2, 3, 4, 5]
# insert(삽입할 위치, 삽입할 데이터) 메서드로 데이터 삽입 (특정 위치에 삽입 가능)
my_list = [1, 2, 3, 4, 5]
my_list.insert(2, 9999) # [1, 2, 9999, 3, 4, 5]
데이터 삭제
# pop(인덱스) 메서드로 특정 위치의 데이터 삭제 및 값 반환
my_list = [1, 2, 3, 4, 5]
popped_element = my_list.pop(2) # 3
print(my_list) # [1, 2, 4, 5]
# remove(데이터 값) 메서드로 특정 데이터 자체를 삭제
my_list = [1, 2, 3, 2, 4, 5]
my_list.remove(2) # [1, 3, 2, 4, 5]
리스트 컴프리헨션으로 데이터에 특정 연산 적용
리스트 컴프리헨션list comprehension은 기존 리스트를 기반해 새 리스트를 만들거나 반복문, 조건문을 이용해 복잡한 리스트를 생성하는 등 다양한 상황에서 사용할 수 있는 문법이다.
# 리스트에 제곱 연산 적용
numbers = [1, 2, 3, 4, 5]
squares = [num**2 for num in numbers] # [1, 4, 9, 16, 25]
# 꿀팁! 리스트 연관 메서드
fruits = ["apple", "banana", "cherry", "apple", "orange", "banana", "kiwi"]
len(fruits) # 7
fruits.index("banana") # 1
fruits.sort( ) # ["apple", "apple", "banana", "banana", "cherry", "kiwi", "orange"]
fruits.count("apple") # 2
# 내림차순 정렬
fruits.sort(reverse=True)- 리스트의 전체 데이터 개수를 반환하는 len( ) 함수
- 특정 데이터가 처음 등장한 인덱스를 반환하는 index( ) 메서드, 없으면 -1 반환
- 사용자가 정한 기준에 따라 리스트 데이터를 정렬하는 sort( ) 메서드
- 특정 데이터 개수를 반환하는 count( ) 메서드
05-4. 몸풀기 문제
* 배열 정렬하기, 배열 제어하기
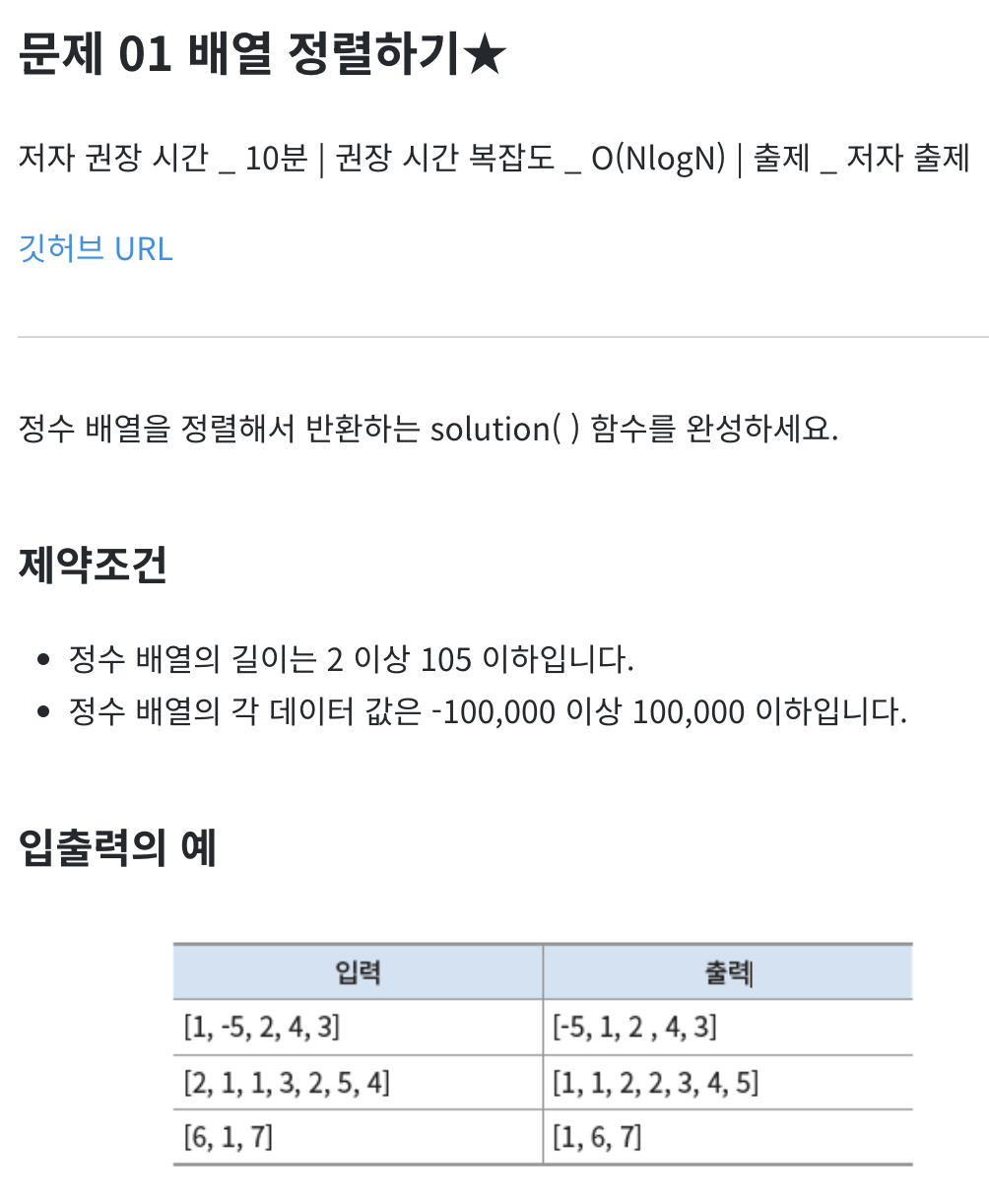
def solution(arr):
arr.sort( ) # arr 원본 변경
return arr
def solution(arr):
sorted_list = list(sort(arr)) # 원본 변경 안됨
return sorted_list# O(N^2) 정렬 알고리즘
import time
def bubble_sort(arr): # 버블 정렬로 정렬하기 O(N^2)
n = len(arr)
for i in range(n):
for j in range(n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
def do_sort(arr): # sort( ) 함수로 배열 정렬하기 O(NlogN)
arr.sort( )
return arr
def measure_time(func, arr): # 시간을 측정하고 뒤집힌 배열 반환
start_time = time.time( )
result = func(arr)
end_time = time.time( )
return end_time - start_time, result
arr = list(range(10000))
# 첫 번째 코드 시간 측정
# 첫 번째 코드 실행 시간 : 3.9616279602 (4초)
bubble_time, bubble_result = measure_time(bubble_sort, arr)
print("첫 번째 코드 실행 시간:", format(bubble_time, ".10f"))
# 두 번째 코드 시간 측정
# 두 번째 코드 실행 시간 : 0.0000560284 (1초 미만)
arr = list(range(10000))
reverse_time, reverse_result = measure_time(do_sort, arr)
print("두 번째 코드 실행 시간:", format(sort_time, ".10f"))
# 두 개의 코드의 결과가 동일한지 확인
print("두 개의 코드의 결과가 동일한지 확인:", bubble_result == sort_result) # True시간 복잡도 : O(NlogN)

def solution(lst):
unique_lst = list(set(lst)) # ➊ 중복값 제거
unique_lst.sort(reverse=True) # ➋ 내림차순 정렬
return unique_lst
➊에서 set( ) 함수를 사용해 배열의 중복값을 제거했습니다. set( )은 집합을 생성하는 내장 함수입니다. 집합은 중복값을 허용하지 않으므로 문제에서 요구하는 중복 문제를 한 번에 해결할 수 있습니다. set( ) 함수는 해시 알고리즘으로 데이터를 저장하므로 시간 복잡도 O(N)을 보장합니다.
➋의 sort( ) 함수 활용 부분에서 reverse 매개변수에 넣은 조건을 확인할 수 있습니다. reverse가 True이면 내림차순, False이면 오름차순(기본값)입니다.
중복 원소 제거 O(N), 정렬 O(NlogN) =>
시간 복잡도 : O(NlogN)
05-5. 모의 테스트
* 두 개 뽑아서 더하기, 모의고사, 행렬의 곱셈, 실패율, 방문 길이
def solution(numbers):
N = len(numbers)
result = []
for i in range(N):
for j in range (i+1, N):
result += [numbers[i]+numbers[j]]
return sorted(set(result))
중복 체크 O(N^2), 정렬 O(N^2log(N^2))
시간 복잡도 : O(N^2log(N^2))
다만 N=100이므로 문제 없음

# 내가 푼 코드
def solution(answers):
N = len(answers)
scores = [0, 0, 0]
examples = [[1, 2, 3, 4, 5], [2, 1, 2, 3, 2, 4, 2, 5], [3, 3, 1, 1, 2, 2, 4, 4, 5, 5]]
omr = []
for idx in range(3):
omr.append([examples[idx][i%len(examples[idx])] for i in range(N)])
for i in range(N):
if omr[0][i] == answers[i]: scores[0]+=1
if omr[1][i] == answers[i]: scores[1]+=1
if omr[2][i] == answers[i]: scores[2]+=1
return [i+1 for i in range(3) if max(scores)==scores[i]]내가 짠 코드는 공간복잡도 나쁜 느낌.
# 답이 일치하는지 확인하는 for문을 아래와 같이 짜자
for i, answer in enumerate(answers):
for j, example in enumerate(examples):
if answer == example[i%len(example)]:
scores[j] += 1
# 예시 코드
def solution(answers):
# ➊ 수포자들의 패턴
patterns = [
[1, 2, 3, 4, 5],
[2, 1, 2, 3, 2, 4, 2, 5],
[3, 3, 1, 1, 2, 2, 4, 4, 5, 5]
]
# ➋ 수포자들의 점수를 저장할 리스트
scores = [0] * 3
# ➌ 각 수포자의 패턴과 정답이 얼마나 일치하는지 확인
for i, answer in enumerate(answers):
for j, pattern in enumerate(patterns):
if answer == pattern[i % len(pattern)]:
scores[j] += 1
# ➍ 가장 높은 점수 저장
max_score = max(scores)
# ➎ 가장 높은 점수를 가진 수포자들의 번호를 찾아서 리스트에 담음
highest_scores = [ ]
for i, score in enumerate(scores):
if score == max_score:
highest_scores.append(i + 1)
return highest_scores패턴, 정답 비교 O(N), 가장높은 점수 추가 연산 O(1)
=> 시간 복잡도 : O(N)
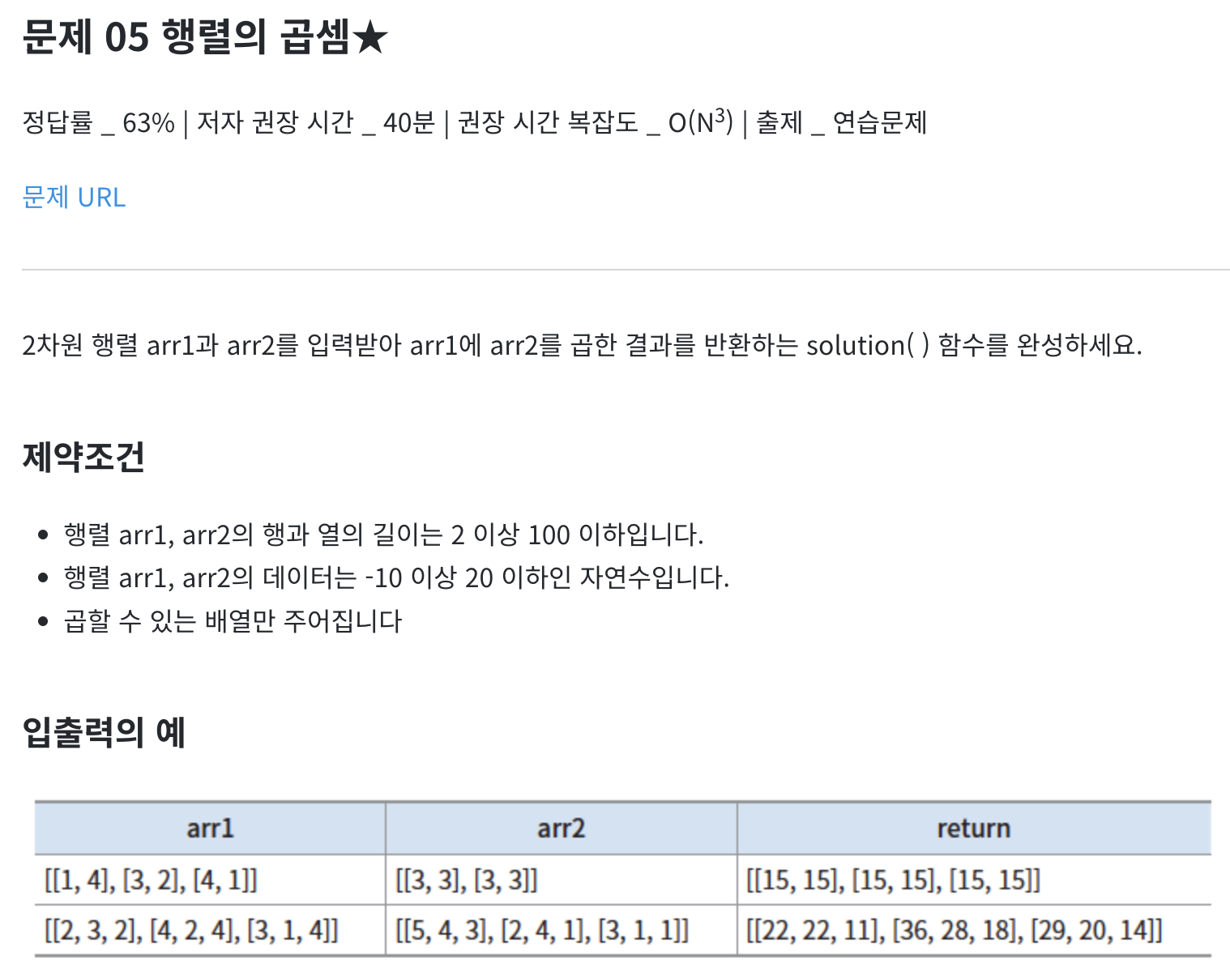
# 예시 코드
def solution(arr1, arr2):
# ➊ 행렬 arr1과 arr2의 행과 열의 수
r1, c1 = len(arr1), len(arr1[0])
r2, c2 = len(arr2), len(arr2[0])
# ➋ 결과를 저장할 2차원 리스트 초기화
ret = [[0] * c2 for _ in range(r1)]
# ➌ 첫 번째 행렬 arr1의 각 행과 두 번째 행렬 arr2의 각 열에 대해
for i in range(r1):
for j in range(c2):
# ➍ 두 행렬의 데이터를 곱해 결과 리스트에 더해줌
for k in range(c1):
ret[i][j] += arr1[i][k] * arr2[k][j]
return ret행렬이 어려워서 답안을 참고함. 저대로 외우자.
시간 복잡도 : r1*c1*c2 -> O(N^3)
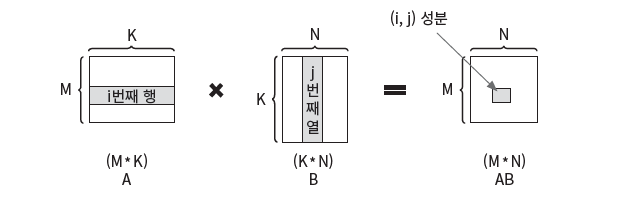
행렬의 곱
A 행렬의 크기가 (M * K), B 행렬의 크기가 (K * N)일 때 두 행렬의 곱 연산은 행렬 A의 길이와 행렬 B의 길이가 같아야 하며 행렬 곱 결과는 (M * N)입니다.

# 내가 짠 코드
def solution(N, stages):
stages.sort()
stageList = [i for i in range(1,N+1)]
failure = [0]*N
P = len(stages)
for i in range(1, N+1):
stageP = stages.count(i)
if P > 0: failure[i - 1] = stageP / P
else: failure[i - 1] = 0
P -= stageP
result = sorted([(f, idx + 1) for idx, f in enumerate(failure)], key=lambda x: (-x[0], x[1]))
return [idx for f, idx in result]사실 내림차순, 오름차순을 어떻게 구현하는지 모르겠어서 key 부분은 검색을 했다....
그런데 효율적이지 않은 코드같다고 느꼈다
.count때문에 시간복잡도 O(N^2)
# 내가 짠 코드 2
def solution(N, stages):
stage_counts = [0] * (N + 1)
for stage in stages:
if stage <= N:
stage_counts[stage] += 1
failure = []
P = len(stages)
for i in range(1, N + 1):
if P > 0:
failure_rate = stage_counts[i] / P
P -= stage_counts[i]
else: failure_rate = 0
failure.append((failure_rate, i))
result = sorted(failure, key=lambda x: (-x[0], x[1]))
return [idx for f, idx in result]count보다 그냥 순회가 낫다고 판단해서 수정
시간 복잡도 : O(N)
# 예시 코드 1
def solution(N, stages):
# ➊ 스테이지별 도전자 수를 구함
challenger = [0] * (N + 2)
for stage in stages:
challenger[stage] += 1
# ➋ 스테이지별 실패한 사용자 수 계산
fails = { }
total = len(stages)
# ➌ 각 스테이지를 순회하며, 실패율 계산
for i in range(1, N + 1):
if challenger[i] == 0 : # ➍ 도전한 사람이 없는 경우, 실패율은 0
fails[i] = 0
else:
fails[i] = challenger[i] / total # ➎ 실패율 구함
total -= challenger[i] # ➏ 다음 스테이지 실패율을 구하기 위해
# 현재 스테이지의 인원을 뺌
# ➐ 실패율이 높은 스테이지부터 내림차순으로 정렬
result = sorted(fails, key=lambda x : fails[x], reverse=True)
return result➊ challenger는 각 스테이지에 도전하는 사용자 수를 저장하는 데 사용하는 배열입니다. 리스트의 크기를 N + 2로 정한 이유도 나름의 문제를 풀기 위한 전략입니다. 왤까요? N번째 스테이지를 클리어한 사용자는 stage가 N + 1입니다. 그러면 challenger 배열에서 N + 1 위치에 데이터를 저장해야 하는데 배열의 인덱스는 0부터 시작하므로 N + 1 인덱스에 데이터를 저장하려면 N + 2 크기의 배열이 필요하기 때문입니다. 물론 이렇게 하면 0번째 인덱스는 사용하지 않아서 낭비라고 생각할 수 있습니다만, 이렇게 하면 실보다 득이 큽니다. 반복문을 보면 각 stages 데이터의 값을 challenger의 인덱스로 사용할 수 있게 됩니다. 이렇게 하면 값 자체를 인덱스로 활용할 수 있어 매우 편리합니다. 메모리 공간 1칸만 비우고 편리함을 취했다고 할 수 있겠네요.
➋ fails는 실패율을 저장하는 용도이고, total의 값은 총 사용자의 수입니다. 해당 변수들이 어떻게 사용되는지는 아래에 자세히 설명하겠습니다.
➌은 이 문제의 핵심입니다. 즉, 실패율을 구하는 로직입니다. 위에서 구한 challengers값을 활용해서 실패율을 구합니다.
➍ 해당 스테이지에 있는 사용자가 0이라면 문제 정의에 의해 실패율은 0이되므로 계산은 간단합니다.
➎ 해당 스테이지에 사용자가 있다면 실패율 공식을 적용해서 실패율을 구합니다. fails는 리스트가 아니고 딕셔너리라는 것을 기억해야 합니다. 다시 말해 fails[i] = challenger[i] / total에서 키는 i, 값은 challengers[i]이며 이 값들이 쌍을 이뤄 fails 딕셔너리 변수에 저장된다고 보면 됩니다. total의 값은 현재 스테이지에 도달한 사용자 값입니다.
➏ N번째 스테이지에 도달한 사용자의 수를 구하려면 N-1번째 스테이지에 있는 사용자의 수를 빼면 됩니다. 예를 들어 3번째 스테이지에 도달한 사용자 수를 구하려면 {1, 2}번째 스테이지에 있는 사용자 수를 제외하면 됩니다. 따라서 총 사용자 수에서 각 스테이지의 인원 수를 빼면 이 값이 다음 스테이지에 도달한 사용자 수가 됩니다. 이러한 이유로 total 값은 초기에는 전체 사용자 수에서 시작해서 각 stage의 실패율을 구할 때마다 현재 stage의 인원을 빼며 코드가 실행됩니다. 설명이 꽤 복잡하지만 다음 그림과 설명을 같이 보면 금방 이해할 수 있습니다.
➐ fails는 딕셔너리입니다. 키는 각 사용자를 가리키는 숫자, 값은 실패율을 의미합니다. 값을 기준으로 키를 정렬해서 반환합니다.

N은 스테이지의 개수이고, M은 stages의 길이입니다. challenger 배열을 초기화하고, 각 스테이지 도전자 수를 계산할 때 시간 복잡도는 O(N + M)입니다. 이후 스테이지 별로 실패율을 계산하는 데 필요한 시간 복잡도는 O(N)이고, 실패율을 기준으로 스테이지를 정렬할 때의 시간 복잡도는 O(NlogN)입니다. 이 연산들을 모두 고려하면 시간 복잡도는 O(2*N + M + NlogN)이므로 최종 시간 복잡도는 O(M + NlogN)입니다.
시간 복잡도 : O(M+NlogN)
예시 코드를 보고 내 코드에 대해 반성했다 . . .
딕셔너리로 풀 수도 있구나. 또한 인덱스를 활용한 방법도 좋은 아이디어라고 생각했다.



# 예시 코드 참고해서 푼 코드
def is_valid_move(nx, ny) :
return -5 <= nx <= 5 and -5 <= ny <= 5
def update_location(x, y, dir) :
if dir == 'U': nx, ny = 0, 1
elif dir == 'D': nx, ny = 0, -1
elif dir == 'L': nx, ny = -1, 0
elif dir == 'R': nx, ny = 1, 0
return nx+x, ny+y
def solution(dirs):
x, y = 0, 0
ans = set()
for dir in dirs :
nx, ny = update_location(x, y, dir)
if not is_valid_move(nx, ny) :
continue
ans.add((x, y, nx, ny))
ans.add((nx, ny, x, y))
x, y = nx, ny
return len(ans)/2# 예시 코드
def is_valid_move(nx, ny) : # ➊ 좌표평면을 벗어나는지 체크하는 함수
return 0 <= nx < 11 and 0 <= ny < 11
def update_location(x, y, dir) : # ➋ 명령어를 통해 다음 좌표 결정
if dir == 'U':
nx, ny = x, y + 1
elif dir == 'D':
nx, ny = x, y - 1
elif dir == 'L':
nx, ny = x - 1, y
elif dir == 'R':
nx, ny = x + 1, y
return nx, ny
def solution(dirs):
x, y = 5, 5
ans = set( ) # ➌ 겹치는 좌표는 1개로 처리하기 위함
for dir in dirs : # ➍ 주어진 명령어로 움직이면서 좌표 저장
nx, ny = update_location(x, y, dir)
if not is_valid_move(nx, ny) : # ➎ 벗어난 좌표는 인정하지 않음
continue
# ➏ A에서 B로 간 경우 B에서 A도 추가해야 함(총 경로의 개수는 방향성이 없음)
ans.add((x, y, nx, ny))
ans.add((nx, ny, x, y))
x, y = nx, ny # ➐ 좌표를 이동했으므로 업데이트
return len(ans)/2첫 번째, 중복 경로는 최종 길이에 포함하지 않는다는 조건입니다. 중복을 포함하지 않는다는 문장이 나오면 set( ) 함수를 생각해보면 좋습니다.
두 번째, 음수 좌표를 포함한다는 점입니다. 문제를 보면 좌표 범위는 -5 <= x, y <= 5입니다. 2차원 배열에서 음수 인덱스를 사용할 수는 없으므로 다른 방법을 생각해야 합니다. 문제의 핵심은 원점에서 출발해 최종 경로의 길이를 구하는 건데, 좌표는 방향에 의해서만 제어된다는 점입니다. 따라서 원점을 (0, 0)에서 (5, 5)로 바꿔 음수 좌표 문제를 해결해도 됩니다. 구현 문제는 답안 코드의 길이가 긴 경우가 많으므로 기능별로 함수를 구현하는 게 좋습니다. 일단 하나의 함수로 전체 동작을 구현해보고 이후 함수로 나누는 연습을 해보기 바랍니다.
➊ 좌표가 주어진 범위를 초과했는지 체크하는 함수입니다. 해당 함수는 좌표 문제에 단골로 등장합니다. 핵심 알고리즘이랑 분리해 가독성을 높였습니다.
➋ 현재 좌표와 방향을 받아 그다음 좌표를 반환하는 함수입니다.
➌ 중복 좌표를 처리하기 위해 ans는 셋으로 정의합니다.
➍ 주어진 명령어 순서대로 순회하는 코드입니다.
➎ 주어진 명령어를 기준으로 다음 좌표를 구하고 해당 좌표가 유효한지 체크합니다. 유효하지 않으면 answer에 좌표를 추가하지 않습니다.
➏ add((x, y, nx, ny))는 (x, y)에서 (nx, ny)까지의 경로를 방문했다라고 기록하는 것을 의미합니다. 이때 (x, y)에서 (nx, ny)만 저장하는 것이 아니라 그 반대인 (nx, ny)에서 (x, y) 역시 추가하는데 이 부분을 이해해야 코드를 제대로 이해한 것이라 할 수 있습니다.
➐ 현재 좌표를 업데이트합니다. A→ B와 B→ A는 이 문제에서는 같은 경로로 취급합니다. 따라서 A→ B인 경우 A→ B와 B→ A를 둘 다 추가하고 나중에 최종 이동 길이를 2로 나눕니다.
못풀겠어서 예시 코드를 참고했다
이미 지나온 길을 어떻게 구현할지가 전혀 감이 안잡혔는데 set함수로 왕복 좌표(?)를 모두 넣어주면 되는게 신박하게 느껴졌다.
시간복잡도 : N은 dirs의 길이 => O(N)
05-5. 추가 문제 (코딩테스트 합격자 되기 박경록 저자님)

def solution(arr):
#arr = [3,4,5,7,2,4,1,1,8,1,3,5,7,6,5,4]
arr.sort()
return [a for a in arr if not a%2]+[a for a in arr if a%2]
시간 복잡도 : O(N)

def solution(nums, k, right):
#nums, k = [1, 2, 3, 4, 5], 2
n = len(nums)
return [nums[(i+n-k)%n] for i in range(n)]
시간 복잡도 : O(N)

def solution(grid):
#grid = [[-1, 0, 0], [0, 0, -1], [0, -1, 0]]
patterns = [[-1, 1], [-1, 0], [-1, -1], [0, 1], [0, -1], [1, 1], [1, 0], [1, -1]]
M, N = len(grid[0]), len(grid)
for y in range(M):
for x in range(N):
if grid[y][x] == -1:
for p in patterns:
ny, nx = p[1]+y, p[0]+x
if 0 <= ny < N and 0 <= nx < M :
if grid[ny][nx] > -1 :
grid[ny][nx] += 1
return gridM * N * 8
시간 복잡도 : O(M*N)
추천 문제 (프로그래머스)
1. 배열의 평균값
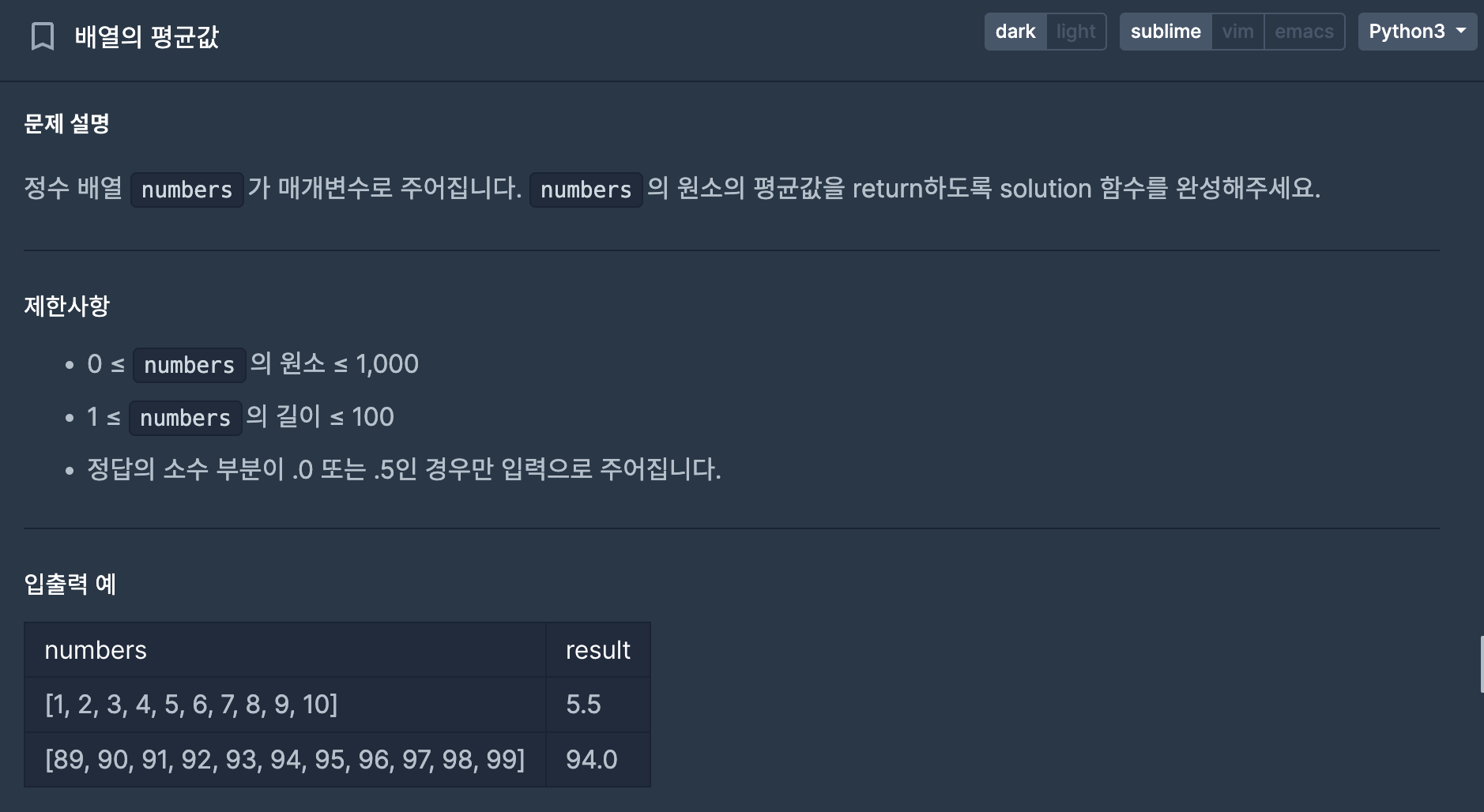
def solution(numbers):
return sum(numbers)/len(numbers)
2. 배열 뒤집기

def solution(num_list):
return num_list[::-1]3. n^2 배열 자르기
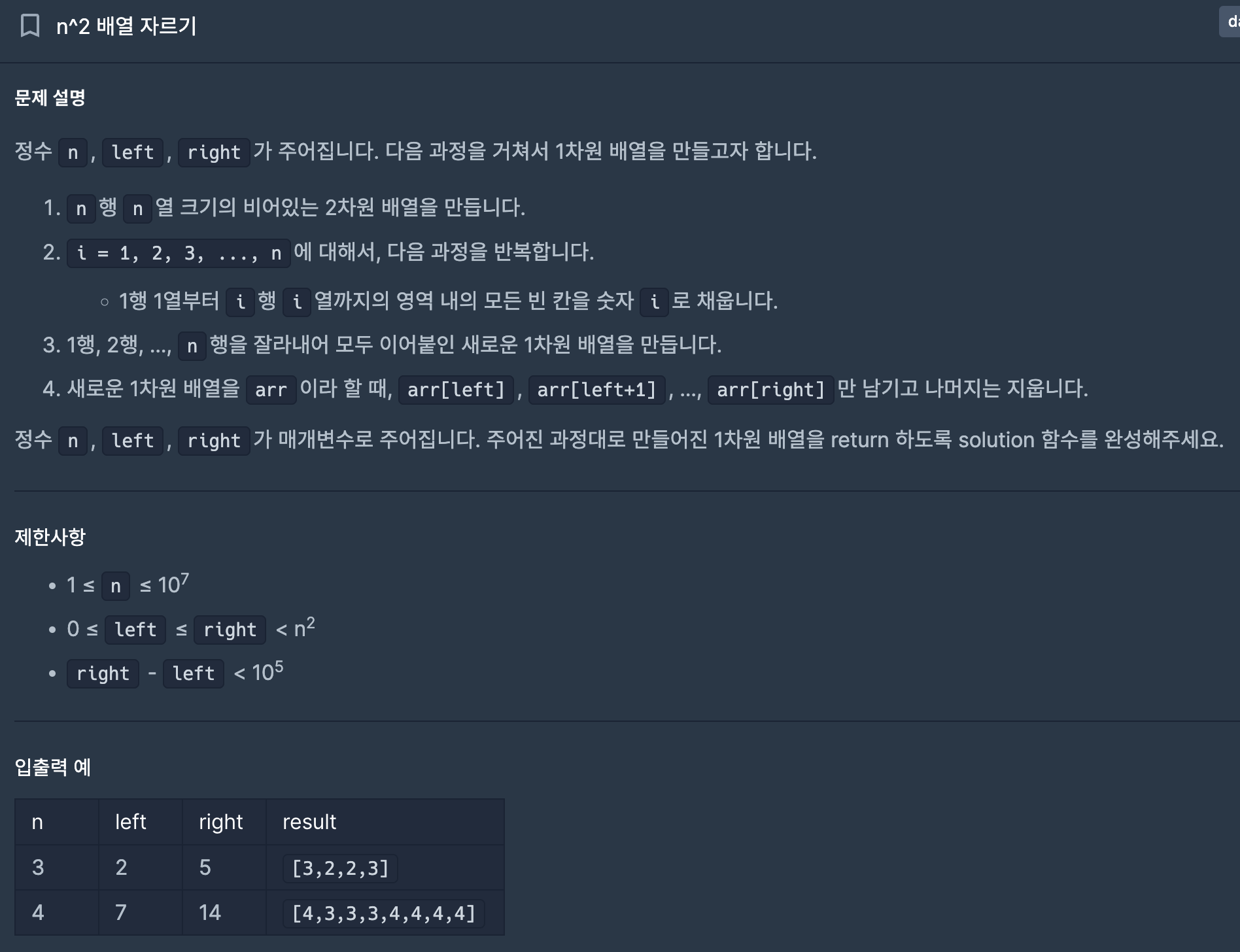
# 처음 짠 코드 (시간 초과 에러)
def solution(n, left, right):
grid = [[0 for _ in range(n)] for _ in range(n)]
for y in range(n):
for x in range(n):
grid[y][x] = max(x, y) + 1
result = []
for g in grid: result += g
return result[left:right+1]시간 초과 없애려고 grid 없애고, 중간에 break문 넣고 등등 해봤으나 에러는 여전히 남.
# 찾아보고 수정한 코드
def solution(n, left, right):
result = []
for index in range(left, right + 1):
y, x = divmod(index, n)
result.append(max(x, y)+1)
return result각 몫과 나머지를 이용하는법... 신박하다.
4. 나누어 떨어지는 숫자 배열
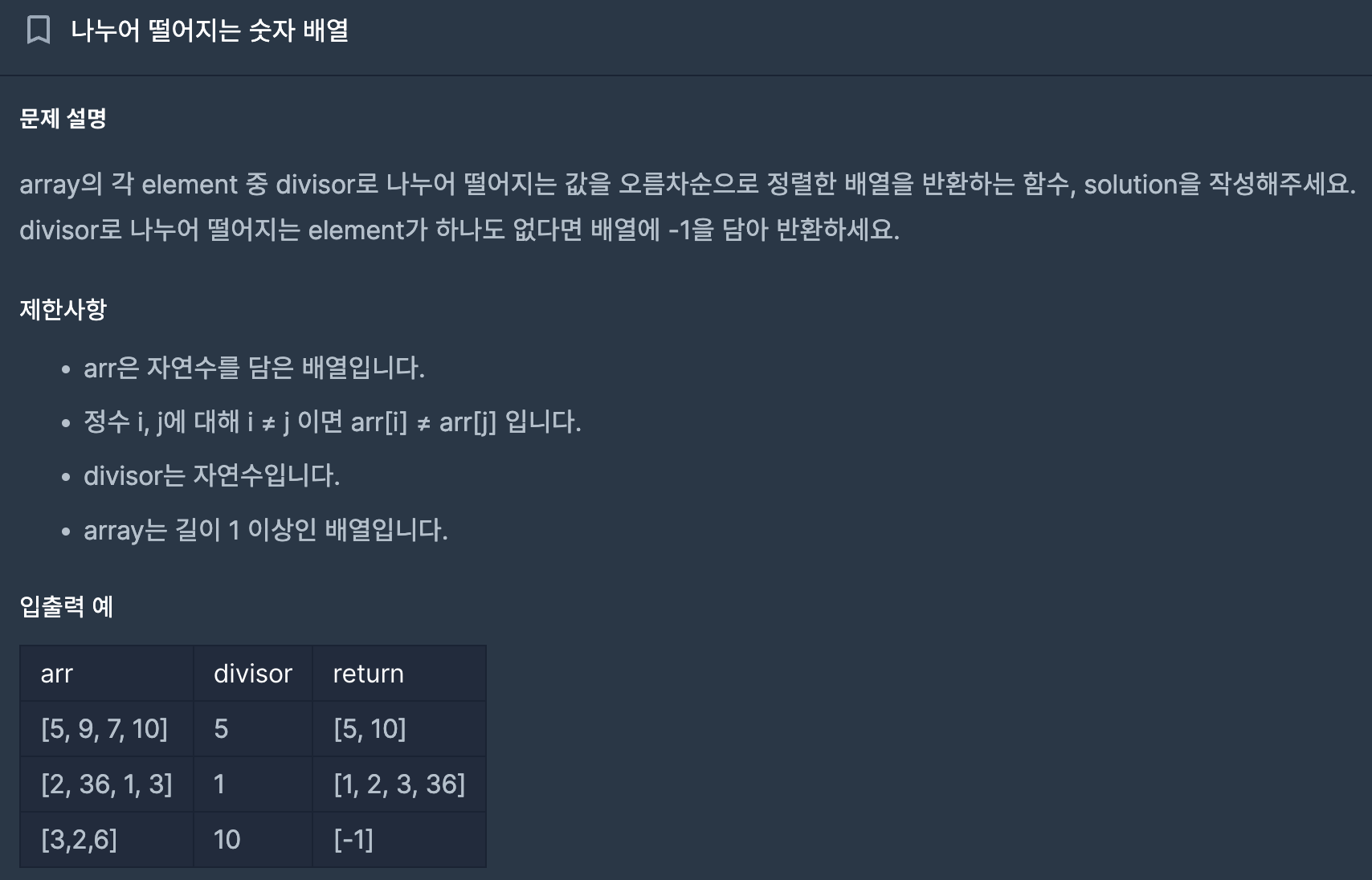
def solution(arr, divisor):
result = [a for a in arr if not a%divisor]
return sorted(result) if result else [-1]정리
- 파이썬에서는 리스트를 배열처럼 사용할 수 있습니다.
- 배열은 임의접근(random access)으로 배열의 모든 위치에 바로 접근할 수 있습니다.
- 중간에 데이터를 삽입할 일이 많다면 배열은 비효율적입니다. 다른 방법을 생각해야 합니다.
출처
https://cafe.naver.com/dremdeveloper/1007
코딩테스트 합격자 되기 - 05 배열
[집중 포인트] 1. 가장 기본적인 자료구조인 배열에 대해서 알아보고, 파이썬에서 배열 대용으로 많이 사용하는 리스트의 특징도 알아봅니다. 2. 배열의 경우에는 구현 시 내...
cafe.naver.com
05 배열
# 공부부터 합격까지 배열 개념에 대해 이해하고 활용하는 방법을 알 수 있습니다. 코딩 테스트 난이도별로 배열 관련 문제를 풀며 여러 함정을 확인하고 이를 해결하는 방법에 익숙…
wikidocs.net
'algorithm > CodingTest' 카테고리의 다른 글
| SQL 코딩테스트 01: WHERE절, HAVING절, 윈도우 함수, CTE, LEFT JOIN (1) | 2024.06.20 |
|---|---|
| [코딩테스트 합격자 되기 - 3주차] 스택 (프로그래머스 문제 풀이) (1) | 2024.01.22 |
| [코딩테스트 합격자 되기 - 1주차] 알고리즘의 효율 분석, 코딩테스트 필수문법 (2) | 2024.01.07 |
| C++ 알고리즘:: 다이나믹 프로그래밍 (0) | 2021.10.30 |
| C++ 알고리즘:: 완전 탐색(Brute-Force) & 백트레킹(Backtracking) (2) | 2021.10.24 |


