
on my way
금융공학4: 군집 분석, 주성분 분석 본문
AI - ML - data -> task
- DL
규칙 패턴
군집 분석 (Clustering)과 주성분 분석 (PCA)의 차이
군집 분석과 주성분 분석은 데이터 분석에서 매우 중요한 두 가지 기법이지만, 목적과 방법에서 큰 차이가 있습니다.
군집 분석 (Clustering)
- 목적:
- 데이터를 유사한 특성을 가진 그룹(군집)으로 나누는 것.
- 각 그룹 내의 데이터는 유사성이 높고, 그룹 간의 데이터는 유사성이 낮도록 함.
- 방법:
- 대표적인 방법으로 K-Means, 계층적 군집 분석, DBSCAN 등이 있음.
- K-Means의 경우, K라는 군집의 수를 미리 정하고, 각 데이터를 가장 가까운 군집 중심(centroid)으로 할당하여 군집화함.
- 사용 사례:
- 고객 세분화: 고객을 유사한 구매 패턴이나 성향을 가진 그룹으로 나눔.
- 문서 분류: 유사한 주제를 가진 문서들을 같은 그룹으로 분류.
주성분 분석 (PCA: Principal Component Analysis)
- 목적:
- 고차원 데이터를 저차원으로 변환하여 주요 정보를 유지하면서 차원을 축소하는 것.
- 데이터의 분산을 최대한 보존하면서 차원을 줄임.
- 방법:
- 데이터의 공분산 행렬을 계산하고, 이를 통해 고유값과 고유벡터를 구함.
- 가장 큰 분산을 설명하는 축을 새로운 주성분으로 설정하고, 데이터를 이 축으로 투영하여 차원을 축소함.
- 사용 사례:
- 차원 축소: 고차원 데이터를 시각화하거나 모델의 성능을 향상시키기 위해 차원을 줄임.
- 잡음 제거: 데이터를 주요 성분으로 투영하여 잡음을 줄이고 주요 패턴을 강조.
왜 사용하는가?
군집 분석의 이유
- 데이터 탐색:
- 데이터를 이해하고, 유사한 특성을 가진 그룹을 식별하여 분석의 방향을 설정하는 데 도움을 줌.
- 개인화:
- 고객 세분화와 같은 개인화된 마케팅 전략을 세우기 위해 사용됨.
- 예를 들어, 각 군집에 맞는 마케팅 캠페인이나 추천 시스템을 설계.
- 이상치 탐지:
- 군집에 속하지 않는 데이터 포인트를 이상치로 간주하여 이상치 탐지에 사용될 수 있음.
주성분 분석의 이유
- 차원 축소:
- 고차원 데이터에서 주요 정보를 유지하면서 차원을 줄여 데이터 시각화나 분석을 쉽게 함.
- 차원이 높은 데이터를 저차원으로 변환하여 처리 속도를 향상시키고, 계산 비용을 줄임.
- 데이터 압축:
- 데이터를 압축하여 저장 공간을 절약하고, 전송 비용을 줄임.
- 잡음 제거:
- 데이터의 주요 패턴을 유지하면서 잡음을 줄여 모델의 성능을 향상시킴.
요약
- 군집 분석은 데이터를 유사한 특성을 가진 그룹으로 나누어 분석의 방향을 설정하고, 개인화된 마케팅 전략을 세우거나 이상치 탐지에 사용합니다.
- 주성분 분석은 데이터를 저차원으로 변환하여 데이터 시각화, 차원 축소, 잡음 제거 등에 사용합니다.
이 두 기법은 데이터 분석에서 서로 보완적인 역할을 하며, 데이터를 더 잘 이해하고 처리하기 위해 함께 사용될 수 있습니다.
1. 군집분석 (Clustering)
군집분석이란?
- Unsupervised Learning: 정답(Y label)이 없는 데이터에서 패턴을 찾는 방법
- Clustering: 비슷한 성격을 가진 데이터끼리 모아주는 작업 (거리가 가까운 관측치들 간 유사한 특징이 있을 것이라는 가정을 기반으로 변수들을 군집화)
- 정답이 없으므로 탐색 인사이트 용도로 사용
- 대부분 optimization 문제를 푸는 경우가 많음
- 목적: 데이터 안에 숨겨진 패턴을 찾아내는 것.
군집분석의 종류
- 계층적 클러스터링 (Hierarchical Clustering)
- 거리행렬을 사용해 유사한(비슷한) 데이터끼리 순차적으로 그룹을 할당
- 덴드로그램(dendrogram)을 통해 데이터가 어떻게 군집을 이루는지 시각화할 수 있어요
- 비계층적 클러스터링 (K-means Clustering)
- 데이터를 몇 개의 그룹으로 나눌지 미리 정한 뒤, 무작위로 시작점을 지정하고 비슷한 데이터끼리 그룹을 할당 (랜덤한 시작점에서 해당 점과 가까운 대상 간 그룹 할당)

군집분석 과정
- 이상치 제거: 데이터에서 이상치(outlier)를 제거해요. (이상치가 존재할 경우 클러스터링 진행 시 영향을 많이 받을 수 있으므로 사전에 제거 과정이 필요)

2. 표준화/스케일링: 데이터의 크기를 맞춰줘요.
from sklearn.preprocessing import StandardScaler
scaled_data = StandardScaler().fit_transform(data)
3. 계층적 클러스터링
Step 1. 거리 계산에 따른 클러스터링
- scipy.cluster.hierarchy의 linkage 사용
- 제공하는 linkage 방식
- single, complete, average, centroid, median, ward, weighted
- 제공하는 거리 계산 방식
- euclidean distance: real-valued 차원에서 각 관측치들의 location을 기반으로 측정 (Euclidean, manhattan, ...)
- centroid, median, ward linkage method를 사용할 경우 Euclidean pairwise metric만 활용 가능
- non-euclidean distance: 각 관측치의 거리가 아닌, properties에 의해 측정 (e.g. cosine, jaccard, ...)
- 이 외에 clustroid 등의 method를 사용할 때 사용 가능
- euclidean distance: real-valued 차원에서 각 관측치들의 location을 기반으로 측정 (Euclidean, manhattan, ...)
- 모든 관측치들 간 거리를 계산함
- 거리를 어떻게 계산할지에 따라 linkage method 구분
1) 최단연결법 (single): 생성된 군집에서 중심과 거리가 가까운 관측치끼리 군집화
2) 최장연결법 (complete): 생성된 군집에서 중심과 거리가 먼 관측치끼리 군집화
3) 평균연결법 (average): 군집 내 모든 데이터와 다른 군집 내 모든 데이터 간의 거리 평균을 계산하여 군집화
4) 중앙연결법 (centroid): 군집 내 centroid과 다른 군집 내 median까지의 거리를 계산하여 가까운 것끼리 군집화
5) 와드연결법 (ward): 거리가 아닌, 군집 내 오차 제곱합(within group sum of squares)이 최소가 되도록 최소가 되도록 군집화

- 장점
- 클러스터 생성 과정에 대해 이해할 수 있음
- 사전에 클러스터의 수를 지정하지 않아도 됨
- 덴드로그램을 통해 클러스터의 수를 결정하는 과정이 쉬움
- 한계
- 방대한 양의 데이터에서 제대로 작동하지 않을 수 있음
- 두 클러스터를 결합한 이후에는 그 전으로 돌아갈 수 없음
- 노이즈 및 이상값에 대해 민감
- 데이터의 순서가 최종 결과에 영향을 줄 수 있음
from scipy.cluster.hierarchy import linkage, dendrogram
clusters = linkage(y=scaled_data, method='complete', metric='euclidean')- 거리를 계산해 비슷한 데이터끼리 묶어줘요.
4. 덴드로그램으로 군집 수 결정
Step 2. 군집 수 결정
- 덴드로그램 (dendrogram): 각 단계에서 군집이 어떻게 형성되는지 확인하고 형성된 군집의 유사성(또는 거리) 수준을 평가
- 덴드로그램을 더 높게 커팅할수록 최종 군집 수는 더 작지만 유사성 수준은 더 낮아짐
- 덴드로그램을 더 낮게 커팅할수록 유사성 수준은 더 높지만 최종 군집 수는 더 많아짐
- 일부 데이터 집합의 경우 평균, 중심, 중위수 및 Ward의 연결 방법으로 계층적 덴드로그램이 생성되지 않음. (결합 거리가 각 단계에서 항상 증가하지 않을 수 있음)
import matplotlib.pyplot as plt
plt.figure(figsize=(25, 10))
dendrogram(clusters, leaf_rotation=90, leaf_font_size=12)
plt.show()
- 덴드로그램을 보고 몇 개의 군집으로 나눌지 결정해요
- - [`fcluster`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.fcluster.html)을 사용하여 덴드로그램 결과에 기반한 clustering을 진행
- 일반적으로는 (cophenetic)`'distance'` threshold(t)를 기준으로 구분
- 이 외에도 inconsistent, maxclust, ... 등의 방식이 있음
5. 군집 평가
- 군집 내 비유사성 (within dissimilarities)는 작고 군집 간 비유사성 (between dissimilarities)는 크도록 생성
- 이 때, Silhouette coefficient (실루엣 계수)는 각 관측치와 주위 관측치과의 거리 계산을 통해 군집 내 비유사성과 군집 간 비유사성의 정도를 평가
- 데이터 양이 많아질수록 time complexity가 높음

- 실루엣 계수(Silhouette Coefficient)를 사용해 군집의 품질을 평가해요.


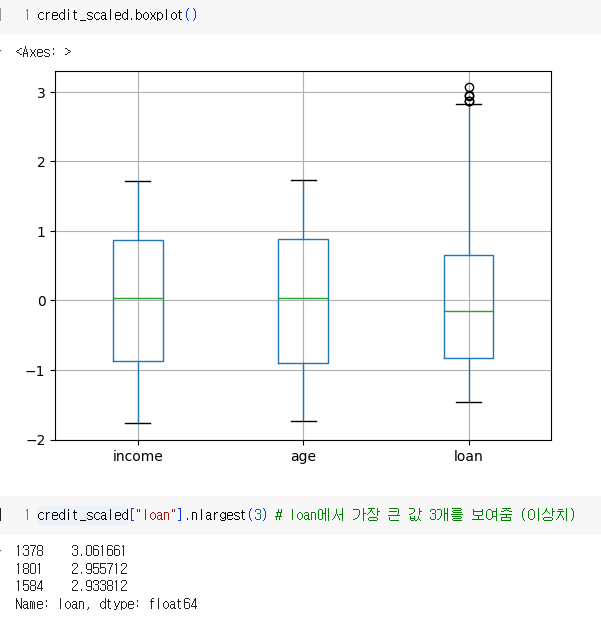
박스플롯 (Box Plot) 해석
박스플롯(Box Plot)은 데이터의 분포와 이상치를 시각적으로 쉽게 이해할 수 있는 도구입니다. 위의 박스플롯은 세 가지 변수인 income, age, loan에 대한 데이터를 나타내고 있습니다. 각 변수의 박스플롯을 개별적으로 해석해볼게요.
박스플롯 구성 요소
- 중앙값 (Median): 박스 내부의 녹색 선으로 표시됩니다. 데이터의 중앙값을 나타냅니다.
- 사분위 범위 (Interquartile Range, IQR): 박스의 상자 부분은 데이터의 1사분위수(Q1)에서 3사분위수(Q3)까지를 나타냅니다. 이 범위는 데이터의 중간 50%를 포함합니다.
- 최솟값 (Minimum)과 최댓값 (Maximum): 수염(whiskers)으로 표시되며, 일반적으로 Q1 - 1.5IQR과 Q3 + 1.5IQR 범위 내의 값을 나타냅니다.
- 이상치 (Outliers): 수염 밖에 위치한 원형 점들로 표시됩니다. 이 값들은 일반적인 범위(Q1 - 1.5IQR과 Q3 + 1.5IQR) 바깥에 있는 값들입니다.
변수별 해석
- income (수입)
- 중앙값은 약 0에 위치하고 있습니다.
- 박스의 상자 부분은 -1에서 1 사이에 있으며, 이는 수입 데이터의 중간 50%가 이 범위에 있음을 나타냅니다.
- 수염은 -2에서 2까지 확장되며, 이는 대부분의 데이터가 이 범위에 있음을 의미합니다.
- 이 변수에는 눈에 띄는 이상치는 없습니다.
- age (나이)
- 중앙값은 약 0에 위치하고 있습니다.
- 박스의 상자 부분은 -1에서 1 사이에 있으며, 이는 나이 데이터의 중간 50%가 이 범위에 있음을 나타냅니다.
- 수염은 -2에서 2까지 확장되며, 이는 대부분의 데이터가 이 범위에 있음을 의미합니다.
- 이 변수에도 눈에 띄는 이상치는 없습니다.
- loan (대출)
- 중앙값은 약 0에 위치하고 있습니다.
- 박스의 상자 부분은 -1에서 1 사이에 있으며, 이는 대출 데이터의 중간 50%가 이 범위에 있음을 나타냅니다.
- 수염은 -2에서 3까지 확장되며, 이는 대부분의 데이터가 이 범위에 있음을 의미합니다.
- loan 변수에는 3보다 큰 값들로 표시된 몇 개의 이상치가 있습니다. 이는 다른 변수들에 비해 대출 데이터에서 극단적인 값들이 존재함을 나타냅니다.
결론
- 모든 변수의 중앙값은 0 근처에 위치해 있으며, 이는 데이터가 대체로 중앙에 모여 있음을 의미합니다.
- income과 age 변수는 이상치가 없으며, 데이터 분포가 균형 잡혀 있습니다.
- loan 변수는 몇 개의 이상치를 포함하고 있으며, 이는 이 변수에서 극단적인 값들이 존재함을 나타냅니다.
이 박스플롯을 통해 각 변수의 데이터 분포와 이상치를 시각적으로 파악할 수 있으며, 이를 기반으로 데이터 전처리나 분석 방향을 결정할 수 있습니다.

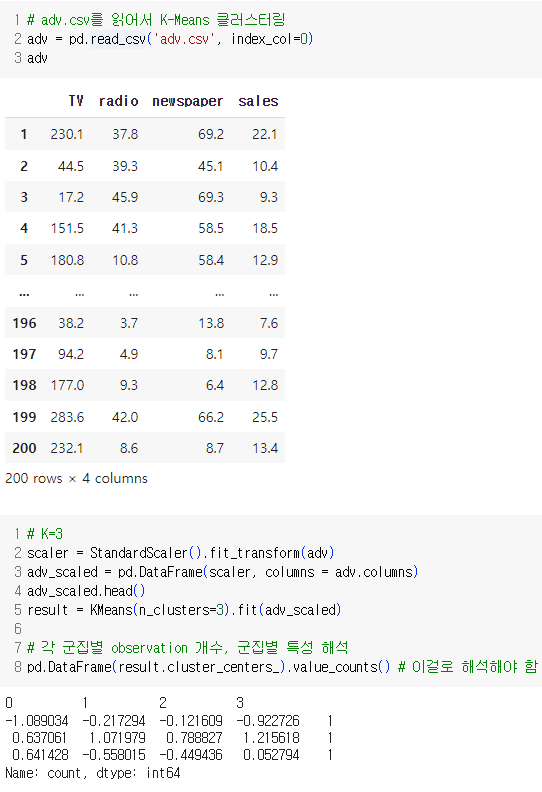
K-Means 클러스터링 결과 해석
K-Means 클러스터링을 통해 데이터를 세 개의 군집으로 나누었고, 각 군집의 중심을 계산했습니다. 각 군집 중심의 좌표는 표준화된 데이터에 기반합니다. 이 중심값을 바탕으로 각 군집의 특성을 해석해 보겠습니다.
군집 중심값 (Cluster Centers)
각 군집의 중심값은 다음과 같습니다:
| 0 | -1.089 | -0.217 | -0.122 | -0.923 |
| 1 | 0.637 | 1.072 | 0.789 | 1.216 |
| 2 | 0.641 | -0.558 | -0.449 | 0.053 |
군집별 특성 해석
군집 0:
- TV 광고액: 평균보다 낮음 (-1.089)
- 라디오 광고액: 평균보다 약간 낮음 (-0.217)
- 신문 광고액: 평균보다 약간 낮음 (-0.122)
- 매출액: 평균보다 낮음 (-0.923)
군집 0은 모든 광고 매체에 평균보다 적은 비용을 지출하며, 이로 인해 매출액도 평균보다 낮은 그룹입니다.
군집 1:
- TV 광고액: 평균보다 높음 (0.637)
- 라디오 광고액: 평균보다 매우 높음 (1.072)
- 신문 광고액: 평균보다 높음 (0.789)
- 매출액: 평균보다 높음 (1.216)
군집 1은 모든 광고 매체에 평균보다 많은 비용을 지출하며, 이로 인해 매출액도 평균보다 높은 그룹입니다. 특히 라디오 광고에 많은 투자를 하고 있습니다.
군집 2:
- TV 광고액: 평균보다 높음 (0.641)
- 라디오 광고액: 평균보다 낮음 (-0.558)
- 신문 광고액: 평균보다 낮음 (-0.449)
- 매출액: 평균에 가까움 (0.053)
군집 2는 TV 광고에 평균보다 많은 비용을 지출하지만, 라디오와 신문 광고에는 평균보다 적은 비용을 지출합니다. 매출액은 거의 평균 수준입니다.
# 각 군집별 관측치 개수 확인
cluster_counts = pd.Series(result.labels_).value_counts()
print(cluster_counts)0 80
1 60
2 60
dtype: int64
군집 0에는 80개의 관측치가 있으며, 군집 1과 군집 2에는 각각 60개의 관측치가 있습니다.
요약
- 군집 0: 광고비 지출이 전반적으로 적고 매출도 낮은 그룹.
- 군집 1: 광고비 지출이 많고 매출도 높은 그룹.
- 군집 2: TV 광고비 지출이 많고, 라디오와 신문 광고비 지출이 적으며 매출은 평균적인 그룹.
이 해석을 바탕으로 각 군집의 특성을 이해하고, 마케팅 전략을 세울 수 있습니다.
주식 데이터를 pykrx에서 가져와 8개의 군집을 찾는 과정입니다. 각 군집의 중심값을 분석합니다.
PyKRX에서 주식 데이터 가져와 8개의 군집 찾기
1. 필요한 라이브러리 설치 및 가져오기
먼저 필요한 라이브러리를 설치하고 가져옵니다. PyKRX 라이브러리는 한국 주식 시장 데이터를 쉽게 가져올 수 있도록 도와줍니다.
# !pip install pykrx
import pandas as pd
from pykrx import stock
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt2. 데이터 가져오기
pykrx 라이브러리를 사용하여 주식 데이터를 가져옵니다. 여기서는 2024년 7월 1일의 데이터를 가져옵니다.
# 데이터 가져오기
df = stock.get_market_ohlcv("20240701")
df.head()3. 데이터 전처리
가져온 데이터를 표준화하여 K-Means 클러스터링에 적합하게 만듭니다
# 데이터 전처리
scaler = StandardScaler().fit_transform(df)
df_scaled = pd.DataFrame(scaler, columns = df.columns)4. K-Means 클러스터링 수행
K-Means 클러스터링을 수행하여 데이터를 8개의 군집으로 나눕니다.
# K-Means 클러스터링
kmeans = KMeans(n_clusters=8, random_state=0).fit(df_scaled)5. 클러스터의 중심값 확인
각 군집의 중심값을 확인하여 군집별 특성을 파악합니다.
kmeans.cluster_centers_ # 각 군집의 중심값6. 클러스터 수에 따른 Inertia 값 확인
클러스터 수에 따라 Inertia 값을 확인하여 적절한 클러스터 수를 찾습니다.
for i in [3, 6, 9, 12, 30, 60]:
kmeans = KMeans(n_clusters=i).fit(df_scaled)
print(i, kmeans.inertia_)7. 결과 분석
각 데이터가 속한 군집을 확인하고, 각 군집의 중심값을 데이터프레임으로 변환합니다.
# 결과 분석
df['cluster'] = kmeans.labels_
cluster_centers = pd.DataFrame(kmeans.cluster_centers_, columns=df.columns[:-1])8. 각 군집별 관측치 개수 확인
각 군집에 속한 데이터의 개수를 확인합니다.
# 각 군집별 관측치 개수
cluster_counts = df['cluster'].value_counts().sort_index()
print("각 군집별 관측치 개수:")
print(cluster_counts)9. 각 군집의 중심값 시각화
군집의 중심값을 시각화하여 군집별 특징을 비교합니다.
# 각 군집의 중심값 시각화
cluster_centers.plot(kind='bar', figsize=(12, 6))
plt.title('Cluster Centers')
plt.xlabel('Cluster')
plt.ylabel('Standardized Value')
plt.show()포스팅 요약
이 포스팅에서는 PyKRX 라이브러리를 사용하여 한국 주식 시장 데이터를 가져와 K-Means 클러스터링을 통해 8개의 군집을 찾는 과정을 설명했습니다. 데이터 전처리부터 클러스터링, 결과 분석 및 시각화까지의 전 과정을 다루었습니다. 이를 통해 각 군집의 특성을 파악하고, 클러스터 수에 따른 Inertia 값을 확인하여 최적의 클러스터 수를 결정하는 방법을 배울 수 있었습니다.
INERTIA란?
Inertia는 KMeans 클러스터링에서 사용하는 군집 내 응집도를 나타내는 척도입니다. 각 데이터 포인트와 해당 포인트가 속한 군집의 중심 사이의 거리를 제곱하여 합산한 값으로, 군집 내 데이터 포인트들이 얼마나 밀집해 있는지를 측정합니다. Inertia 값이 낮을수록 군집 내 데이터 포인트들이 중심에 더 가깝게 모여 있다는 의미입니다. 즉, 낮은 Inertia 값은 더 좋은 군집화를 나타냅니다.
KMeans 클러스터링할 때 스케일링해야 하는 이유
KMeans 클러스터링에서 스케일링이 중요한 이유는 각 변수의 크기가 다를 경우, 클러스터링 결과에 영향을 줄 수 있기 때문입니다. KMeans는 유클리드 거리를 사용하여 군집화를 수행하는데, 변수의 값의 범위가 다르면 큰 값을 가지는 변수가 거리에 더 큰 영향을 미칩니다. 예를 들어, 한 변수는 0에서 1까지의 값을 갖고 다른 변수는 0에서 1000까지의 값을 가진다면, 후자의 변수는 거리를 계산할 때 더 큰 영향을 미치게 됩니다. 스케일링을 통해 모든 변수의 값을 같은 범위로 맞춰줌으로써 이러한 문제를 해결할 수 있습니다.
StandardScaler란?
StandardScaler는 데이터의 각 특징(feature)을 표준화(standardization)하는데 사용되는 도구입니다. 표준화는 데이터를 평균이 0, 표준편차가 1이 되도록 변환하는 것을 의미합니다. 이를 통해 각 특징이 동일한 스케일을 가지게 되어 클러스터링 시 특정 특징이 과도하게 영향을 미치는 것을 방지할 수 있습니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit_transform(data)클러스터 수에 따라 달라지는 것
클러스터 수(K)가 달라지면 다음과 같은 변화가 생깁니다:
- Inertia: 클러스터 수가 증가하면 일반적으로 Inertia 값은 감소합니다. 이는 각 데이터 포인트가 더 가까운 클러스터 중심에 속하게 되어 군집 내 응집도가 높아지기 때문입니다. 하지만 클러스터 수가 너무 많아지면 과적합(overfitting)이 발생할 수 있습니다.
- 클러스터 중심: 클러스터 수가 달라지면 클러스터 중심의 위치가 바뀝니다. 클러스터 수가 많아질수록 데이터 분포를 더 세분화하여 표현할 수 있습니다.
- 군집 내 데이터 개수: 각 군집에 속하는 데이터 포인트의 개수가 달라집니다. 클러스터 수가 많아지면 각 군집에 속하는 데이터 포인트의 수가 적어질 수 있습니다.
클러스터 수가 많을수록 발생할 수 있는 문제
- 과적합 (Overfitting): 클러스터 수를 너무 많이 설정하면, 모델이 데이터의 세부적인 부분까지 과도하게 맞추게 됩니다. 이는 일반화 능력이 떨어지는 모델을 만들게 되어 새로운 데이터에 대해서는 성능이 저하될 수 있습니다.
- 해석의 어려움: 클러스터 수가 많으면 각 클러스터를 해석하고 이해하기 어려워집니다. 클러스터가 너무 많으면 데이터를 분류한 목적이 퇴색될 수 있습니다.
- 효율성 문제: 클러스터 수가 많아지면 계산량이 증가하여 모델 학습 시간과 비용이 증가합니다. 이는 특히 큰 데이터셋에서 문제가 될 수 있습니다.
적절한 클러스터 수를 결정하는 방법
- 엘보우 방법 (Elbow Method): 클러스터 수에 따른 Inertia(또는 SSE: Sum of Squared Errors)를 계산하여 그래프로 그립니다. 클러스터 수가 증가할수록 Inertia가 감소하는데, 감소율이 급격히 줄어드는 지점을 찾아 그 지점을 클러스터 수로 선택합니다. 이 지점을 '엘보우'라 부릅니다.
- 실루엣 계수 (Silhouette Score): 각 데이터 포인트의 실루엣 계수를 계산하여 클러스터링의 품질을 평가합니다. 실루엣 계수는 -1에서 1 사이의 값을 가지며, 값이 클수록 좋은 군집화를 의미합니다. 평균 실루엣 계수가 가장 높은 클러스터 수를 선택합니다.
- 분산 비율 (Variance Ratio Criterion, Calinski-Harabasz Index): 군집 간 분산과 군집 내 분산의 비율을 계산하여 클러스터링의 품질을 평가합니다. 값이 높을수록 좋은 군집화를 의미합니다.
예시
엘보우 방법과 실루엣 계수를 사용하는 예시는 다음과 같습니다:
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
inertia = []
silhouette_scores = []
# 클러스터 수를 1에서 10까지 변경하며 평가
for k in range(1, 11):
kmeans = KMeans(n_clusters=k, random_state=0).fit(df_scaled)
inertia.append(kmeans.inertia_)
if k > 1:
score = silhouette_score(df_scaled, kmeans.labels_)
silhouette_scores.append(score)
# 엘보우 방법 그래프
plt.figure(figsize=(10, 5))
plt.plot(range(1, 11), inertia, 'bo-')
plt.xlabel('Number of Clusters')
plt.ylabel('Inertia')
plt.title('Elbow Method for Optimal k')
plt.show()
# 실루엣 계수 그래프
plt.figure(figsize=(10, 5))
plt.plot(range(2, 11), silhouette_scores, 'bo-')
plt.xlabel('Number of Clusters')
plt.ylabel('Silhouette Score')
plt.title('Silhouette Scores for Optimal k')
plt.show()value_counts()란?
value_counts()는 pandas의 Series 객체에서 사용되는 메소드로, 각 고유 값의 출현 빈도를 계산하여 반환합니다. 예를 들어, 군집 레이블이 저장된 Series에서 value_counts()를 사용하면 각 군집에 속하는 데이터 포인트의 개수를 계산할 수 있습니다.
# 예시
df['cluster'].value_counts()위 코드는 df 데이터프레임의 'cluster' 열에서 각 클러스터에 속하는 데이터 포인트의 개수를 계산합니다.
종합 정리
- Inertia: 군집 내 데이터 포인트들이 군집 중심에 얼마나 가까이 모여 있는지를 나타내는 척도. 값이 낮을수록 더 좋은 군집화.
- 스케일링의 중요성: 변수의 크기 차이가 클러스터링 결과에 영향을 미치지 않도록 변수들을 동일한 스케일로 맞춰주는 과정.
- StandardScaler: 데이터를 표준화하여 평균이 0, 표준편차가 1이 되도록 변환하는 도구.
- 클러스터 수의 변화: 클러스터 수에 따라 Inertia 값, 클러스터 중심의 위치, 각 군집에 속하는 데이터 포인트의 개수 등이 달라짐.
- value_counts(): Series 객체에서 각 고유 값의 출현 빈도를 계산하여 반환하는 메소드.
이해하기 쉽게 설명하였으니, 이제 KMeans 클러스터링을 실행할 때 필요한 개념들을 충분히 이해할 수 있을 것입니다.
2. 주성분 분석 (PCA)
주성분 분석이란?
- 차원의 저주: 데이터의 변수(차원)가 많아지면 분석이 어려워져요.
- PCA: 데이터를 중요한 정보만 남기고 차원을 줄이는 방법이에요.
PCA의 가정
- 데이터는 선형적이다.
- 큰 분산을 가지는 축이 중요한 정보를 가진다.
PCA 과정
- 데이터 표준화
from sklearn.preprocessing import StandardScaler
data_scaled = StandardScaler().fit_transform(data)- 모든 데이터의 크기를 맞춰줘요.
2. 공분산 행렬 계산
- 데이터의 변동성을 계산해요.
data_cov = np.cov(data_scaled.T)3. 주성분 선택
- 몇 개의 주성분(Principal Component)을 사용할지 결정해요.
from sklearn.decomposition import PCA
pca = PCA(n_components=6)
principal_components = pca.fit_transform(data_scaled)4. Scree Plot으로 주성분 수 결정
- Scree Plot을 보고 몇 개의 주성분을 사용할지 결정해요.
import matplotlib.pyplot as plt
plt.figure()
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('Number of Components')
plt.ylabel('Explained Variance')
plt.show()5. PCA 적용
- 주성분을 사용해 데이터를 변환해요.
요약
- 군집분석: 데이터 안에 비슷한 데이터끼리 그룹을 만드는 방법이에요.
- 주성분 분석 (PCA): 데이터를 중요한 정보만 남기고 차원을 줄이는 방법이에요.
이 두 가지 분석 방법을 통해 데이터를 효율적으로 분석하고, 숨겨진 패턴을 찾을 수 있어요.
주성분 분석 (PCA: Principal Component Analysis)
1. 차원의 저주 (Curse of Dimensionality)
- 차원의 저주란 변수(차원)가 증가함에 따라 데이터가 희소(sparse)해지는 현상을 말합니다.
- 예를 들어, 축구장에서 친구를 찾는 것보다 서울시 전체에서 친구를 찾는 게 더 어렵죠. 변수가 많아질수록 이렇게 데이터 간의 유사성을 찾기 어려워져요.
- 고차원 공간에서는 무작위로 선택한 두 점 사이의 평균 거리가 멀어지며, 데이터 간의 유사성을 판단하기 어려워집니다.
- 이를 해결하기 위해 엄청나게 많은 데이터를 확보할 수 있지만, 차원이 늘어날수록 필요한 데이터의 양이 기하급수적으로 증가하여 현실적으로 불가능합니다.
2. 차원 축소 방법
- 저차원 투영: 고차원 데이터를 저차원으로 투영하여 차원을 축소합니다. ( 데이터를 중요한 정보만 남기고 차원을 줄이는 방법)
- 매니폴드 학습: 데이터를 매니폴드(manifold)에 맞추어 차원을 축소하는 방법이지만, 시각화에 유리하나 다루기 까다롭고 느립니다.
3. 주성분 분석 (PCA)
- PCA는 데이터를 저차원으로 투영하여 중요한 정보를 유지하면서 차원을 축소하는 기법입니다.
- 고차원 데이터에서 분산을 최대한 보존하는(데이터를 잘 설명하는) 방향으로 축을 설정하고, 데이터를 이 축으로 투영합니다.
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import numpy as np
# 데이터 로드
boston = pd.read_csv("BostonHousing.csv")
# 'chas'와 'rad' 변수 제거
boston.drop(["chas", "rad"], axis=1, inplace=True)
# 데이터 스케일링
scaler = StandardScaler()
scaled = pd.DataFrame(scaler.fit_transform(boston), columns=boston.columns)
# 주성분 분석
pca = PCA()
pc = pca.fit_transform(scaled)
# 설명된 분산의 누적 비율
cumsum = np.cumsum(pca.explained_variance_ratio_)
print("누적 분산 설명 비율:", cumsum)
# 데이터 형태 확인
print("원본 데이터 형태:", boston.shape)
print("주성분 분석 후 데이터 형태:", pc.shape)코드 설명
- 데이터 로드 및 전처리:
- boston 데이터셋을 로드합니다.
- 'chas'와 'rad' 변수는 분석에 포함되지 않으므로 제거합니다.
- 스케일링:
- PCA를 적용하기 전에 데이터 스케일링을 수행하여 각 변수의 분산을 고정합니다.
- StandardScaler를 사용하여 데이터를 표준화합니다.
- 주성분 분석 (PCA):
- PCA 객체를 생성하고, 스케일링된 데이터를 입력하여 주성분 분석을 수행합니다. ( PCA를 이용해서 데이터를 중요한 방향으로 변환해요.)
- pca.explained_variance_ratio_를 통해 각 주성분이 설명하는 분산의 비율을 구하고, 이를 누적합(np.cumsum)하여 누적 분산 설명 비율을 계산합니다. ( 각 주성분이 데이터를 얼마나 잘 설명하는지 비율을 구해서 누적합(np.cumsum)으로 보여줘요.)
- 결과 확인:
- 원본 데이터의 형태와 PCA를 통해 변환된 데이터의 형태를 비교합니다.
- 누적 분산 설명 비율을 출력하여 주성분이 원본 데이터의 분산을 얼마나 잘 설명하는지 확인합니다.
주성분 분석의 필요성
- 차원 축소: 고차원 데이터를 저차원으로 축소하여 분석과 시각화를 용이하게 합니다. ( 변수가 많을 때 중요한 정보만 남기고 줄여줘요)
- 노이즈 제거: 주요 정보만 남기고 노이즈를 제거하여 데이터의 패턴을 더 명확하게 파악할 수 있습니다. ( 주요 정보만 남기고 불필요한 데이터를 제거해요.)
- 모델 성능 향상: 차원이 줄어듦에 따라 변수가 줄어들어 모델의 학습 속도가 빨라지고, 과적합을 방지할 수 있습니다.
PCA는 데이터를 더 잘 이해하고, 중요한 정보를 추출하며, 분석을 용이하게 만드는 데 유용한 기법입니다. 이 예제는 BostonHousing 데이터를 사용하여 PCA를 적용하는 방법과 그 결과를 시각화하는 방법을 보여줍니다.
주성분 분석(PCA)에서 pc[:,0:5]와 같은 코드를 사용하여 처음 5개의 주성분만 선택하는 이유는 보통 다음과 같습니다:
1. 차원 축소
PCA의 주요 목적 중 하나는 데이터의 차원을 축소하는 것입니다. 모든 주성분을 사용하는 대신, 데이터를 대표할 수 있는 소수의 주성분만 선택하여 계산의 복잡성을 줄이고 데이터의 해석을 용이하게 합니다.
2. 정보 보존
PCA는 주성분을 설명하는 분산의 비율을 계산합니다. 처음 몇 개의 주성분이 데이터의 대부분의 변동성을 설명할 수 있다면, 나머지 주성분은 무시할 수 있습니다.
3. 과적합 방지
너무 많은 주성분을 사용하면 모델이 과적합(overfitting)될 수 있습니다. 과적합은 모델이 훈련 데이터에 너무 맞춰져서 새로운 데이터에 대한 일반화 성능이 떨어지는 상황을 말합니다. 따라서, 주요 주성분만 사용하여 모델의 일반화 능력을 향상시킬 수 있습니다.
예제: 처음 5개의 주성분 선택
먼저, 주성분 분석을 통해 각 주성분이 설명하는 분산 비율을 확인합니다.
import numpy as np
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 예시 데이터
boston = pd.read_csv("BostonHousing.csv")
boston.drop(["chas", "rad"], axis=1, inplace=True)
# 데이터 스케일링
scaler = StandardScaler()
scaled = pd.DataFrame(scaler.fit_transform(boston), columns=boston.columns)
# PCA 수행
pca = PCA()
pc = pca.fit_transform(scaled)
# 각 주성분의 분산 비율
explained_variance = np.cumsum(pca.explained_variance_ratio_)
print(explained_variance)
# explained_variance 출력 예시:
array([0.3, 0.5, 0.6, 0.7, 0.8, 0.85, 0.9, 0.92, 0.94, 0.96, 0.97, 0.98, 0.99])
이 예시에서 처음 5개의 주성분은 약 80%의 분산을 설명합니다. 이는 데이터를 처음 5개의 주성분으로 축소해도 전체 데이터의 대부분의 정보를 보존할 수 있음을 의미합니다.
따라서, 다음과 같이 처음 5개의 주성분을 선택합니다:
# 처음 5개의 주성분 선택
pc_first_5 = pc[:, 0:5]
print(pc_first_5)요약
처음 5개의 주성분을 선택하는 이유는:
- 차원을 효과적으로 축소하여 계산 효율성을 높임
- 데이터의 대부분의 정보를 보존
- 모델의 과적합을 방지
이러한 이유들로 인해 주성분 분석에서는 보통 처음 몇 개의 주성분만 선택하여 사용합니다.
과적합 (Overfitting)
과적합이란?
과적합은 머신러닝 모델이 학습 데이터에 너무 잘 맞춰져서 새로운 데이터에 대한 예측 성능이 떨어지는 현상을 말해요. 쉽게 말해서, 모델이 학습 데이터의 패턴뿐만 아니라 노이즈까지 학습해버려서, 실제 데이터를 예측할 때 성능이 좋지 않게 되는 거예요.
과적합의 예시
예를 들어, 시험 공부를 할 때, 기출문제만 외우고 시험을 보면, 그 기출문제와 비슷한 문제는 잘 풀 수 있어요. 하지만 기출문제와 다른 새로운 문제가 나오면 잘 못 풀 수 있죠. 이게 과적합과 비슷한 상황이에요. 기출문제(학습 데이터)에는 잘 맞지만, 실제 시험(새로운 데이터)에서는 성적이 안 나오는 거죠.
과적합의 원인
- 모델이 너무 복잡할 때: 모델이 너무 복잡해서 학습 데이터에 있는 모든 작은 패턴과 노이즈까지 학습해버려요.
- 학습 데이터가 적을 때: 데이터가 충분하지 않아서 모델이 일반화되지 않고, 학습 데이터에만 맞춰져요.
- 특성이 많을 때: 모델이 고려해야 할 특성이 많아서 과적합이 발생할 수 있어요.
과적합 방지 방법
- 데이터를 더 많이 사용하기: 더 많은 데이터를 사용하면 모델이 일반화되기 쉬워져요.
- 모델의 복잡도를 줄이기: 모델을 단순화해서 과적합을 방지할 수 있어요.
- 정규화 (Regularization): 모델이 과적합되지 않도록 패널티를 부여해요.
- 교차 검증 (Cross-Validation): 데이터를 여러 번 나누어 학습하고 평가해서 과적합을 방지해요.
- 드롭아웃 (Dropout): 학습 중 일부 뉴런을 무작위로 꺼서 과적합을 방지해요. (주로 딥러닝에서 사용)
주성분 분석과 군집 분석
이번 포스팅에서는 주성분 분석(PCA)과 군집 분석(K-Means)을 결합하여 데이터를 효과적으로 분석하는 방법을 소개합니다.
1. 데이터 전처리
먼저, 데이터를 스케일링하고 주성분 분석(PCA)을 수행하여 주요 주성분을 추출합니다.
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
# 데이터 불러오기
boston = pd.read_csv("BostonHousing.csv")
boston.drop(["chas", "rad"], axis=1, inplace=True)
# 데이터 스케일링
scaler = StandardScaler()
scaled = pd.DataFrame(scaler.fit_transform(boston), columns=boston.columns)
# 주성분 분석(PCA)
pca = PCA()
pc = pca.fit_transform(scaled)
# 처음 5개의 주성분 선택
pc_first_5 = pc[:, 0:5]2. 최적의 클러스터 수 선택
K-Means 군집 분석에서 클러스터 수(K)를 선택하는 것은 중요한 단계입니다. 여기서는 6, 9, 12개의 클러스터에 대해 각각의 inertia(관성) 값을 계산하여 최적의 K를 선택합니다.
# 6, 9, 12개의 클러스터에 대해 inertia 값 계산
for i in [6, 9, 12]:
print(f"K={i}: Inertia={KMeans(n_clusters=i).fit(pc_first_5).inertia_}")Inertia는 클러스터 내의 샘플들이 얼마나 가깝게 모여있는지를 측정하는 값입니다. 일반적으로 inertia 값이 작을수록 클러스터링이 잘 되었다고 판단할 수 있습니다.
3. 최적의 K로 군집 분석 수행
최적의 K로 결정된 9개의 클러스터에 대해 K-Means 군집 분석을 수행합니다.
# 최적의 K=9로 K-Means 군집 분석 수행
kc = KMeans(n_clusters=9).fit(pc_first_5)
print("클러스터 중심:\n", kc.cluster_centers_)4. 결과 해석
각 클러스터의 중심을 확인하여 클러스터의 특성을 해석합니다. 클러스터 중심은 각 주성분에서의 평균 값을 나타내며, 이를 통해 각 클러스터가 데이터의 어떤 특성을 공유하는지 이해할 수 있습니다.
요약
- 데이터를 스케일링하고 주성분 분석(PCA)으로 차원을 축소했습니다.
- 6, 9, 12개의 클러스터에 대해 K-Means 군집 분석을 수행하고 inertia 값을 비교하여 최적의 클러스터 수를 선택했습니다.
- 최적의 K=9로 K-Means 군집 분석을 수행하고 각 클러스터의 중심을 확인했습니다.
이 과정은 데이터의 주요 특성을 유지하면서 효율적으로 분석할 수 있는 방법을 제공합니다. 주성분 분석으로 차원을 축소하고, 군집 분석으로 데이터의 패턴을 찾는 것은 데이터 분석에서 매우 유용한 기술입니다.
예시 문제
1. 데이터 수집 및 전처리
먼저, 주성분 분석을 위해 데이터를 스케일링하고 표준화합니다.
import pandas as pd
from pykrx import stock
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
# 데이터 수집
df = stock.get_market_fundamental('20240701')
print(df.head())
# 데이터 스케일링
scaler = StandardScaler()
scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
# 주성분 분석(PCA)
pca = PCA()
pc = pca.fit_transform(scaled)
print(pc)2. 주성분 분석
PCA를 통해 데이터의 주성분을 추출하고, 누적 설명 분산 비율을 확인합니다.
# 누적 설명 분산 비율 계산
explained_variance_ratio_cumsum = np.cumsum(pca.explained_variance_ratio_)
print(explained_variance_ratio_cumsum)
# 누적 설명 분산 비율이 80%에서 85%를 차지하는 주성분 선택
num_components = np.argmax(explained_variance_ratio_cumsum >= 0.80) + 1
print(f"80% 설명하는 주성분 개수: {num_components}")
num_components = np.argmax(explained_variance_ratio_cumsum >= 0.85) + 1
print(f"85% 설명하는 주성분 개수: {num_components}")3. 최적의 클러스터 수 선택
K-Means 군집 분석에서 클러스터 수(K)를 선택하는 것은 중요한 단계입니다. 여기서는 80%와 85%를 설명하는 주성분을 사용하여 각각의 inertia(관성) 값을 계산하여 최적의 K를 선택합니다.
# 80%와 85% 설명하는 주성분들로 K-Means 군집 분석 수행
for i in [6, 9, 12]:
inertia_80 = KMeans(n_clusters=i).fit(pc[:, :num_components]).inertia_
print(f"K={i}, 80% 설명하는 주성분: Inertia={inertia_80}")
inertia_85 = KMeans(n_clusters=i).fit(pc[:, :num_components]).inertia_
print(f"K={i}, 85% 설명하는 주성분: Inertia={inertia_85}")4. 최적의 K로 군집 분석 수행
최적의 K로 결정된 클러스터에 대해 K-Means 군집 분석을 수행합니다.
# 최적의 K로 K-Means 군집 분석 수행
optimal_k = 9
kc = KMeans(n_clusters=optimal_k).fit(pc[:, :num_components])
print("클러스터 중심:\n", kc.cluster_centers_)
# 정답
KMeans(n_clusters=8).fit(pc[:,:4]).cluster_centers_5. 결과 해석
각 클러스터의 중심을 확인하여 클러스터의 특성을 해석합니다. 클러스터 중심은 각 주성분에서의 평균 값을 나타내며, 이를 통해 각 클러스터가 데이터의 어떤 특성을 공유하는지 이해할 수 있습니다.
요약
- 데이터 수집 및 전처리: 주식 시장의 기초 데이터를 수집하고, 표준화를 통해 데이터를 스케일링했습니다.
- 주성분 분석(PCA): 주성분 분석을 통해 데이터를 차원 축소하고, 누적 설명 분산 비율을 확인하여 주요 주성분을 선택했습니다.
- 최적의 클러스터 수 선택: 80%와 85%의 설명 분산 비율을 차지하는 주성분을 사용하여 각각의 클러스터 수(K)에 대해 inertia 값을 계산했습니다.
- 최적의 K로 군집 분석 수행: 최적의 K=9로 K-Means 군집 분석을 수행하고 각 클러스터의 중심을 확인했습니다.
이 과정은 데이터를 효율적으로 분석하고, 주식 시장의 기초 데이터를 통해 군집을 찾는 데 유용한 방법을 제공합니다.
예시문제2
Boston Housing 데이터셋으로 주성분 분석(PCA)과 회귀 모델 만들기
이번 포스팅에서는 Boston Housing 데이터셋을 사용하여 주성분 분석(PCA)을 수행하고, 이를 기반으로 회귀 모델을 만드는 과정을 알아보겠습니다.
1. 데이터 준비 및 전처리
먼저, 데이터를 읽어오고 필요한 전처리 과정을 거칩니다.
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LinearRegression
# 1. 데이터 읽기
boston = pd.read_csv("BostonHousing.csv")
# 2. 'chas'와 'rad' 컬럼을 제외하기
boston.drop(["chas","rad"], axis=1, inplace=True)
# 3. 데이터 스케일링 (표준화)
scaler = StandardScaler()
scaled = pd.DataFrame(scaler.fit_transform(boston), columns=boston.columns)설명:
- 데이터 읽기: BostonHousing.csv 파일에서 데이터를 읽어옵니다.
- 컬럼 제외: chas와 rad 컬럼을 데이터에서 제외합니다. axis=1은 열을 기준으로 삭제하라는 뜻입니다.
- 데이터 스케일링: StandardScaler를 사용하여 데이터를 표준화합니다. 표준화는 데이터의 각 특징을 평균이 0, 표준편차가 1이 되도록 변환하는 과정입니다.
2. 주성분 분석 (PCA)
이제 데이터를 주성분 분석(PCA)을 통해 차원 축소합니다
# 4. 'medv' 컬럼을 제외한 나머지 데이터로 주성분 분석
Xs = scaled.drop("medv", axis=1)
# 5. 주성분 분석 (PCA) 수행
pca = PCA()
pc = pca.fit_transform(Xs)
# 6. 누적 설명 분산 비율 확인
np.cumsum(pca.explained_variance_ratio_)설명:
- 'medv' 컬럼 제외: 'medv'는 우리가 예측하고자 하는 목표값(target)이기 때문에 제외합니다.
- PCA 수행: PCA를 사용하여 차원 축소를 수행합니다. 이는 데이터의 주요 정보를 최대한 보존하면서 데이터의 차원을 줄이는 과정입니다.
- 누적 설명 분산 비율 확인: np.cumsum을 사용하여 각 주성분이 데이터의 분산을 얼마나 설명하는지 누적 비율을 확인합니다.
3. 회귀 모델 만들기
이제 주성분 분석 결과를 사용하여 회귀 모델을 만듭니다.
# 7. 주성분 중 중요한 5개의 주성분을 사용하여 회귀 모델 만들기
model = LinearRegression()
model.fit(pc[:,:5], scaled["medv"])
# 8. 회귀 모델의 계수 확인
print(model.coef_)설명:
- 회귀 모델 만들기: 중요한 5개의 주성분을 사용하여 LinearRegression 모델을 만듭니다. pc[:,:5]는 첫 5개의 주성분을 의미합니다.
- 계수 확인: 회귀 모델의 계수를 확인합니다. 계수는 각 주성분이 'medv' 값에 얼마나 영향을 미치는지를 나타냅니다.
회귀란?
회귀(Regression)란 두 변수 간의 관계를 분석하여 하나의 변수를 다른 변수로 예측하는 통계 기법입니다. 여기서 우리는 주성분을 사용하여 집 값('medv')을 예측합니다. 주성분이 집 값에 얼마나 영향을 미치는지 알아내기 위해 회귀 모델을 사용합니다.
회귀 분석이란?
회귀 분석은 예측 모델을 만들기 위한 통계 기법 중 하나입니다. 쉽게 말해, 어떤 변수(입력값)를 가지고 다른 변수(결과값)를 예측하는 방법이에요.
예를 들어보자면:
- 입력 변수(독립 변수): 공부한 시간
- 결과 변수(종속 변수): 시험 점수
공부한 시간이 많을수록 시험 점수가 높아질 가능성이 높다고 생각할 수 있죠? 이 관계를 숫자로 표현하는 게 바로 회귀 분석입니다.
회귀 분석의 목표
회귀 분석은 입력 변수와 결과 변수 사이의 관계를 찾는 것입니다. 이 관계를 이용해서 새로운 입력값에 대해 결과값을 예측할 수 있게 됩니다.
회귀 방정식
회귀 분석의 결과는 보통 다음과 같은 형태의 방정식으로 나타납니다:

결과값으로 알 수 있는 것
- 계수(coefficient, coef_): 각 입력 변수가 결과 변수에 미치는 영향을 나타냅니다. 예를 들어, 공부한 시간이 1시간 늘어날 때 시험 점수가 몇 점 늘어나는지를 알 수 있습니다.
- 절편(intercept): 입력 변수가 0일 때 결과 변수가 얼마인지를 나타냅니다. 예를 들어, 공부를 전혀 하지 않았을 때 예상되는 시험 점수를 알 수 있습니다.
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LinearRegression
# 1. 데이터 읽기
boston = pd.read_csv("BostonHousing.csv")
# 2. 'chas'와 'rad' 컬럼을 제외하기
boston.drop(["chas", "rad"], axis=1, inplace=True)
# 3. 데이터 스케일링 (표준화)
scaler = StandardScaler()
scaled = pd.DataFrame(scaler.fit_transform(boston), columns=boston.columns)
# 4. 'medv' 컬럼을 제외한 나머지 데이터로 주성분 분석
Xs = scaled.drop("medv", axis=1)
pca = PCA()
pc = pca.fit_transform(Xs)
# 5. 누적 설명 분산 비율 확인
explained_variance_ratio_cumsum = np.cumsum(pca.explained_variance_ratio_)
print(explained_variance_ratio_cumsum)
# 6. 주요 주성분을 사용하여 회귀 모델 만들기
model = LinearRegression()
model.fit(pc[:, :5], scaled["medv"])
# 7. 회귀 모델의 계수 확인
print("회귀 모델의 계수:", model.coef_)예제 설명
- 데이터 읽기:
- BostonHousing.csv 파일을 읽습니다.
- 컬럼 제외:
- chas와 rad 컬럼을 데이터에서 제외합니다.
- 데이터 스케일링:
- 데이터를 표준화하여 평균이 0, 표준편차가 1이 되도록 변환합니다.
- 주성분 분석(PCA):
- medv 컬럼을 제외한 나머지 컬럼으로 주성분 분석을 수행합니다. 이는 데이터의 차원을 축소하고 중요한 특징을 추출하는 과정입니다.
- 누적 설명 분산 비율 확인:
- 주성분들이 데이터의 분산을 얼마나 설명하는지 누적 비율을 확인합니다.
- 회귀 모델 만들기:
- 주요 주성분 5개를 사용하여 회귀 모델을 만듭니다.
- 회귀 모델의 계수 확인:
- 회귀 모델의 계수를 출력하여 각 주성분이 결과 변수(medv)에 얼마나 영향을 미치는지 확인합니다.
이 과정을 통해 우리는 데이터의 중요한 특징을 추출하고, 이를 바탕으로 예측 모델을 만들 수 있습니다. 이 모델을 사용하면 새로운 데이터를 입력했을 때 결과를 예측할 수 있게 됩니다.
원-핫 인코딩(One-Hot Encoding)
원 핫 인코딩은 컴퓨터가 이해할 수 있도록 범주형 데이터를 숫자로 변환하는 방법 중 하나입니다.
쉽게 설명하자면:
우리가 설문 조사에서 사람들의 좋아하는 색깔을 "빨강", "파랑", "초록"이라고 기록했다고 해봅시다. 컴퓨터는 이 글자를 이해하지 못합니다. 그래서 이 정보를 숫자로 바꿔야 합니다.
방법:
- 각 범주(색깔)에 고유한 숫자를 부여합니다.
- 이 숫자를 이진(0과 1)으로 변환합니다.
예를 들어:
- "빨강"을 [1, 0, 0]
- "파랑"을 [0, 1, 0]
- "초록"을 [0, 0, 1]
이렇게 변환합니다.
예제
우리가 "A", "B", "A"라는 데이터를 가지고 있다고 해볼게요. 이 데이터를 원 핫 인코딩하면 어떻게 될까요?
원-핫 인코딩은 범주형 데이터를 수치형 데이터로 변환하는 기법입니다. 예를 들어, 'A', 'B'와 같은 범주형 데이터를 숫자로 변환해야 머신러닝 모델에서 사용할 수 있습니다. 이를 위해 pd.get_dummies를 사용합니다.
# 범주형 데이터 원-핫 인코딩
categories = ["A", "B", "A"]
one_hot_encoded = pd.get_dummies(categories)
print(one_hot_encoded)설명:
- pd.get_dummies: 범주형 데이터를 원-핫 인코딩으로 변환합니다. 결과는 'A'와 'B'를 각각 0과 1로 표현하여 머신러닝 모델에 사용할 수 있게 합니다.

이 테이블을 보면:
- 첫 번째 "A"는 [1, 0]으로 인코딩됩니다.
- 두 번째 "B"는 [0, 1]으로 인코딩됩니다.
- 세 번째 "A"는 다시 [1, 0]으로 인코딩됩니다.
왜 원 핫 인코딩을 사용하나요?
- 컴퓨터가 이해할 수 있게:
- 컴퓨터는 문자 데이터를 직접 처리할 수 없습니다. 숫자로 변환해야 계산할 수 있습니다.
- 범주형 데이터 간의 관계를 명확히:
- "빨강", "파랑", "초록"은 순서가 없지만, 단순히 숫자로 변환하면 순서가 있는 것처럼 착각할 수 있습니다. 예를 들어, "빨강"을 1, "파랑"을 2, "초록"을 3으로 변환하면, 파랑이 빨강보다 크고 초록이 파랑보다 크다는 잘못된 의미를 줄 수 있습니다. 원 핫 인코딩은 이런 문제를 해결해줍니다.
- 원 핫 인코딩은 범주형 데이터를 숫자로 변환하는 방법입니다.
- 각 범주를 고유한 벡터로 변환하여 컴퓨터가 이해할 수 있도록 합니다.
- 이를 통해 컴퓨터는 정확한 데이터 처리를 할 수 있습니다.
요약
- 데이터 준비: 데이터를 읽어오고, 필요한 컬럼을 제외한 후 스케일링(표준화)합니다.
- 주성분 분석(PCA): PCA를 통해 데이터를 차원 축소하고, 누적 설명 분산 비율을 확인하여 주요 주성분을 선택합니다.
- 회귀 모델 만들기: 중요한 주성분을 사용하여 회귀 모델을 만들고, 회귀 계수를 확인합니다.
- 원-핫 인코딩(One-Hot Encoding): 범주형 데이터를 수치형 데이터로 변환합니다.
이 과정을 통해 우리는 데이터를 효율적으로 분석하고, 집 값을 예측할 수 있는 모델을 만들 수 있습니다. 주성분 분석(PCA)은 차원을 줄여 데이터의 주요 정보를 유지하고, 회귀 모델은 이 정보를 사용하여 예측을 수행합니다.
'etc' 카테고리의 다른 글
| 금융공학6: ANN 기초부터 TensorFlow를 활용한 심층 신경망 구현까지 (1) | 2024.08.17 |
|---|---|
| 금융공학5: 리스크 관리와 포트폴리오 최적화: 데이터 분석과 CAPM 모델 활용 (0) | 2024.08.16 |
| 금융공학3: 시계열 분석과 데이터 전처리 (ARIMA 모델) (0) | 2024.08.14 |
| 금융공학2: 주식 시장의 주요 용어와 금융 지표 (0) | 2024.08.14 |
| 금융공학1: 금융 공학 개요 (0) | 2024.06.28 |



