
on my way
금융공학7: RNN과 LSTM을 활용한 시계열 데이터 예측 실습 본문
RNN 이해 및 실습
1. 시계열 데이터
시계열 데이터는 시간에 따라 변하는 데이터를 의미합니다. 예를 들어, 주식 가격, 날씨 데이터 등이 있습니다.
예제 시계열 만들기
import numpy as np
import matplotlib.pyplot as plt
# 배열 만들기
xarr = np.array([100,200,300,400])
yarr = np.array([1,2,3,4])
cond = ([True, False, True, False])
# 조건에 따라 xarr 또는 yarr 선택
np.where(cond, xarr, yarr) # cond가 True면 xarr, False면 yarr
# 랜덤 시드 설정
np.random.seed(2020)시계열 데이터 시각화
plt.figure(figsize=(10, 5))
plt.title('TimeSeries Data')
plt.xlabel('Time')
plt.ylabel('Value')
plt.plot(np.arange(0, 30 * 11 + 1), time_series[:30 * 11 + 1], color='black', alpha=0.7, label='train') # 학습용 데이터
plt.plot(np.arange(30 * 11, 30 * 12 + 1), time_series[30 * 11:], color='orange', label='test') # 테스트용 데이터
plt.legend()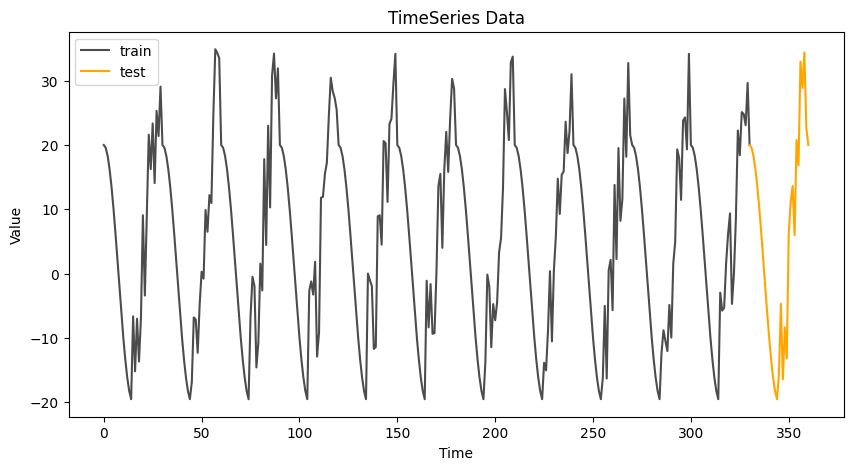

이 부분은 시계열 데이터의 예시를 보여주고 있는 것입니다. 예를 들어, 시간의 흐름에 따라 값이 어떻게 변하는지를 나타내고 있습니다. (각각 시간에서의 값)
time_series[0:10]은 시계열 데이터의 처음 10개의 값을 보여줍니다. 아래는 이 값들의 의미를 쉽게 설명한 내용입니다.
- X축 (시간): 시간 단계를 나타냅니다.
- Y축 (값): 시계열의 값을 나타냅니다.
- 학습 데이터 (검은 선): 모델을 학습시키기 위해 사용되는 데이터 부분입니다.
- 테스트 데이터 (주황색 선): 모델의 성능을 평가하기 위해 사용되는 데이터 부분입니다.
신경망에서의 사용:
- 학습 데이터: 모델이 패턴을 인식하도록 가르치는 데 사용됩니다.
- 테스트 데이터: 모델의 성능을 평가하는 데 사용됩니다.
2. 시계열 데이터 전처리: Sequence 만들기
시퀀스는 시간에 따라 연속적으로 나열된 데이터입니다. 예를 들어, 매일의 기온, 매 시간의 주식 가격, 매년의 인구수 등이 시퀀스 데이터입니다. 시퀀스 데이터를 분석해서 미래를 예측할 수 있습니다.
def make_sequence(time_series, n):
x_train, y_train = list(), list()
for i in range(len(time_series)):
x = time_series[i:(i + n)]
if (i + n) < len(time_series):
x_train.append(x)
y_train.append(time_series[i + n])
else:
break
return np.array(x_train), np.array(y_train)이 함수는 주어진 시계열 데이터를 n 크기의 슬라이딩 윈도우로 나눕니다. x는 입력 데이터, y는 예측해야 하는 다음 값입니다.
n = 15
x_train, y_train = make_sequence(time_series, n)
x_train = x_train.reshape(-1, n, 1)
y_train = y_train.reshape(-1, 1)
print(x_train.shape)
print(y_train.shape)- x_train: (346, 15, 1)
- y_train: (346, 1)
3. 데이터 분할
from sklearn.model_selection import train_test_split
partial_x_train = x_train[:30 * 11]
partial_y_train = y_train[:30 * 11]
x_test = x_train[30 * 11:]
y_test = y_train[30 * 11:]
print('train:', partial_x_train.shape, partial_y_train.shape)
print('test:', x_test.shape, y_test.shape)- 학습 데이터: (330, 15, 1)
- 테스트 데이터: (16, 15, 1)
Sequence 함수 확인
시계열 데이터에서 일정한 크기의 슬라이딩 윈도우를 사용해 데이터를 생성하는 예시
test_arr = np.arange(100)
a, b = make_sequence(test_arr, 15)
for i in range(1, 4):
print(a[i], '|', b[i])- test_arr = np.arange(100):
- 0부터 99까지의 숫자를 갖는 배열을 만듭니다. 이 배열은 [0, 1, 2, ..., 99]가 됩니다.
- a, b = make_sequence(test_arr, 15):
- make_sequence 함수는 길이가 15인 시퀀스 데이터를 만듭니다.
- a는 입력 데이터 (x_train), b는 출력 데이터 (y_train)입니다.
- for i in range(1, 4): print(a[i], '|', b[i]):
- a와 b에서 1번째부터 3번째까지의 데이터를 출력합니다.
make_sequence 함수
이 함수는 길이가 n인 슬라이딩 윈도우를 사용해 입력 데이터 a와 출력 데이터 b를 만듭니다. 예제를 통해 더 자세히 살펴보겠습니다.
예제 설명
test_arr가 [0, 1, 2, ..., 99]일 때, make_sequence(test_arr, 15)는 다음과 같이 작동합니다:
- 첫 번째 슬라이딩 윈도우:
- 입력 데이터 (a[0]): [0, 1, 2, ..., 14]
- 출력 데이터 (b[0]): 15
- 두 번째 슬라이딩 윈도우:
- 입력 데이터 (a[1]): [1, 2, 3, ..., 15]
- 출력 데이터 (b[1]): 16
- 세 번째 슬라이딩 윈도우:
- 입력 데이터 (a[2]): [2, 3, 4, ..., 16]
- 출력 데이터 (b[2]): 17
이와 같이 시퀀스를 만들면서 윈도우를 하나씩 이동해 데이터를 생성합니다. 예제를 통해 a와 b를 출력한 결과는 다음과 같습니다:

- 첫 번째 슬라이딩 윈도우: [1, 2, 3, ..., 15]는 출력 16과 연결됩니다.
- 두 번째 슬라이딩 윈도우: [2, 3, 4, ..., 16]는 출력 17과 연결됩니다.
- 세 번째 슬라이딩 윈도우: [3, 4, 5, ..., 17]는 출력 18과 연결됩니다.
이와 같이 입력 시퀀스와 출력 값을 짝지어 데이터를 생성합니다. 이를 통해 시계열 데이터를 예측할 수 있는 모델을 학습시킬 수 있습니다.
4. SimpleRNN 구축

1. 쌍곡선 탄젠트 (tanh) 및 시그모이드 활성화 함수
설명: 이 그래프는 두 가지 활성화 함수인 tanh와 sigmoid를 비교합니다.
- Sigmoid (파란 선): 시그모이드 함수는 0과 1 사이의 값을 출력합니다. 함수는 σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}로 정의됩니다.
- Tanh (빨간 선): 탄젠트 함수는 -1과 1 사이의 값을 출력합니다. 함수는 tanh(x)=ex−e−xex+e−x\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}로 정의됩니다.
- 신경망에서의 사용:
- Sigmoid: 이진 분류 작업의 출력 층에서 주로 사용됩니다.
- Tanh: 숨겨진 층에서 주로 사용되며, -1과 1 사이의 값을 출력하여 더 강한 음수 값을 모델링할 수 있습니다.
from tensorflow.keras.layers import SimpleRNN, Dense
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(SimpleRNN(units=32, activation='tanh', input_shape=(n, 1))) # SimpleRNN 층 추가
model.add(Dense(1, activation='linear')) # 출력층
model.compile(optimizer='adam', loss='mse') # 모델 컴파일
model.summary()SimpleRNN (단순 순환 신경망)
SimpleRNN은 시퀀스 데이터를 처리하는 신경망의 한 종류입니다. SimpleRNN은 과거의 정보(이전 시간의 데이터)를 현재의 정보와 결합하여 결과를 예측합니다. 시계열 데이터에서 많이 사용됩니다.
Units (유닛)
유닛은 신경망 층에서의 뉴런(노드) 개수를 의미합니다. 예를 들어, units=32는 해당 층에 32개의 뉴런이 있음을 의미합니다.
Activation (활성화 함수)
활성화 함수는 신경망에서 입력 신호를 출력 신호로 변환하는 함수입니다. 예를 들어, tanh는 입력 값을 -1에서 1 사이로 변환합니다. relu는 입력 값이 양수일 때 그대로 출력하고, 음수일 때는 0을 출력합니다.
Input Shape (입력 형태)
Input Shape은 신경망에 입력되는 데이터의 형태를 의미합니다. 예를 들어, input_shape=(15, 1)은 15개의 시퀀스 데이터가 하나씩 입력된다는 의미입니다.
Dense (밀집층)
Dense는 모든 입력이 모든 출력과 연결된 신경망 층입니다. 완전히 연결된 층이라고도 합니다. 예를 들어, Dense(1)은 하나의 뉴런으로 구성된 밀집층을 의미합니다.
Optimizer (최적화 알고리즘)
Optimizer는 신경망의 학습 과정을 최적화하는 알고리즘입니다. 예를 들어, adam은 자주 사용되는 최적화 알고리즘으로, 학습 속도를 조절하고 손실 함수를 최소화합니다.
Loss (손실 함수)
Loss는 신경망의 예측 값과 실제 값의 차이를 나타내는 함수입니다. 손실 함수의 값을 최소화하는 것이 학습의 목표입니다. 예를 들어, mse는 평균 제곱 오차로, 예측 값과 실제 값의 차이를 제곱하여 평균을 구한 값입니다.
모델 학습
model.fit(x_train, y_train, epochs=30, batch_size=1)배치는 한 번에 처리하는 데이터의 묶음입니다. 예를 들어, 한꺼번에 32개의 데이터를 처리하는 것을 32 배치라고 합니다. 배치를 사용하면 컴퓨터 메모리를 효율적으로 사용할 수 있습니다.
Epoch (에포크)
에포크는 전체 데이터를 한 번 학습하는 과정입니다. 예를 들어, 100개의 데이터를 32 배치로 학습하면, 전체 데이터를 세 번 학습해야 합니다(100/32 ≈ 3). 이 세 번의 학습 과정을 세 에포크라고 합니다.
5. 예측 vs 실제 값(Actual) 시각화
pred = model.predict(x_test)
pred_range = np.arange(len(y_train), len(y_train) + len(pred))
plt.figure(figsize=(15, 5))
plt.title('Prediction')
plt.xlabel('Time')
plt.ylabel('Value')
plt.plot(pred_range, y_test.reshape(-1,), color='orange', label='actual')
plt.plot(pred_range, pred.reshape(-1,), color='blue', label='prediction')
plt.legend()
plt.show()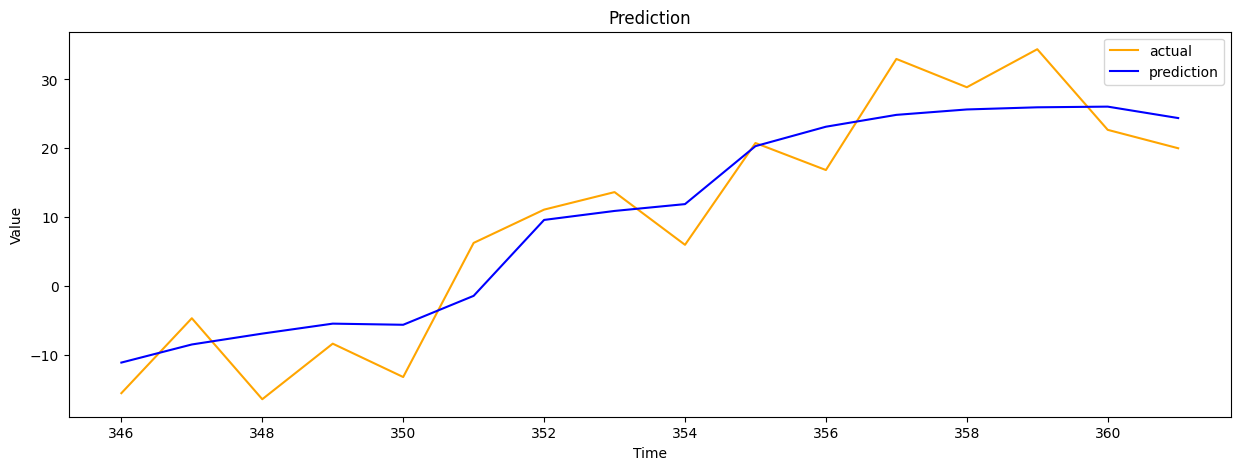
3. 예측 대 실제 (첫 번째 모델)
설명: 이 그래프는 모델의 예측 값과 실제 값을 비교합니다.
- X축 (시간): 시간 단계를 나타냅니다.
- Y축 (값): 예측 값과 실제 값을 나타냅니다.
- 실제 값 (주황색 선): 데이터셋의 실제 값입니다.
- 예측 값 (파란 선): 모델이 예측한 값입니다.
6. LSTM 사용 및 예측 결과
LSTM은 더 복잡한 시계열 데이터를 잘 처리하는 신경망입니다.
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import SGD
LSTM_model = Sequential()
LSTM_model.add(LSTM(units=50, activation='tanh', input_shape=(n, 1), return_sequences=True))
LSTM_model.add(LSTM(units=50, activation='tanh'))
LSTM_model.add(Dense(1, activation='linear'))
LSTM_model.compile(optimizer=SGD(learning_rate=0.01, momentum=0.9, nesterov=False), loss='mse')
LSTM_model.fit(x_train, y_train, epochs=50, batch_size=150)예측 결과 시각화
pred = model.predict(x_test)
pred_range = np.arange(len(y_train), len(y_train) + len(pred))
plt.figure(figsize=(15, 5))
plt.title('Prediction')
plt.xlabel('Time')
plt.ylabel('Value')
plt.plot(pred_range, y_test.reshape(-1,), color='orange', label='actual')
plt.plot(pred_range, pred.reshape(-1,), color='blue', label='prediction')
plt.legend()
plt.show()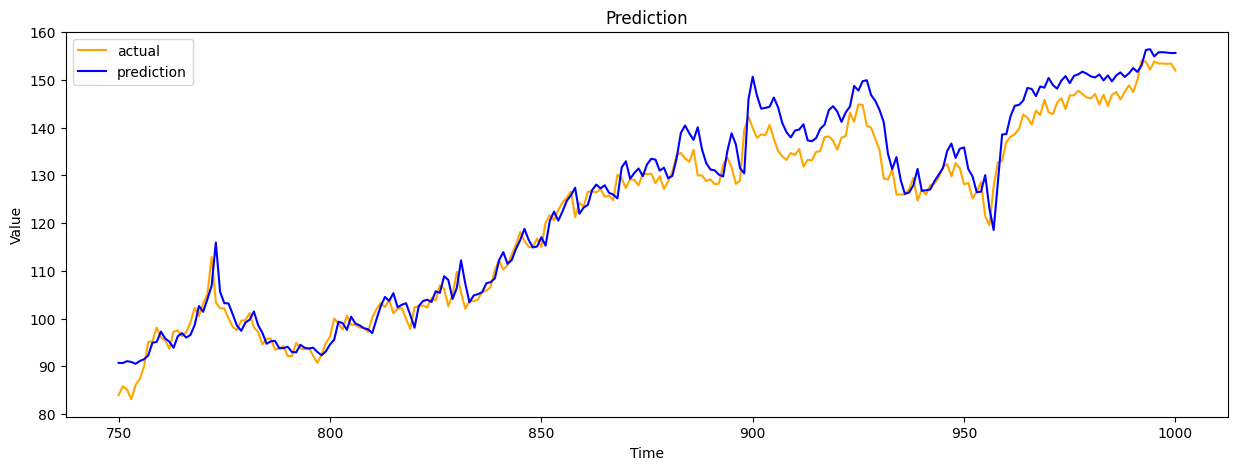
예측 대 실제 (두 번째 모델)
- X축 (시간): 시간 단계를 나타냅니다.
- Y축 (값): 예측 값과 실제 값을 나타냅니다.
- 실제 값 (주황색 선): 데이터셋의 실제 값입니다.
- 예측 값 (파란 선): 모델이 예측한 값입니다.
신경망에서의 사용:
- 평가: 예측 값과 실제 값을 비교하여 모델의 성능을 평가하는 데 도움을 줍니다.
설명
- 시계열 데이터: 시간에 따라 변하는 데이터입니다. 주식 가격, 날씨 등.
- SimpleRNN: 시계열 데이터를 처리하는 신경망입니다.
- LSTM: 복잡한 시계열 데이터를 처리하는 더 강력한 신경망입니다.
- 학습: 모델이 데이터를 보고 패턴을 배우는 과정입니다.
- 예측: 학습한 모델이 새로운 데이터를 예측하는 과정입니다.
'etc' 카테고리의 다른 글
| 금융공학8: 결정 트리와 앙상블 방법을 이용한 머신러닝 모델 구축 및 분석 (0) | 2024.08.30 |
|---|---|
| 금융공학8: 결정 트리와 앙상블 기법을 활용한 머신러닝 모델 비교와 실습 (0) | 2024.08.19 |
| 금융공학6: ANN 기초부터 TensorFlow를 활용한 심층 신경망 구현까지 (1) | 2024.08.17 |
| 금융공학5: 리스크 관리와 포트폴리오 최적화: 데이터 분석과 CAPM 모델 활용 (0) | 2024.08.16 |
| 금융공학4: 군집 분석, 주성분 분석 (0) | 2024.08.15 |



