

on my way
금융공학8: 결정 트리와 앙상블 방법을 이용한 머신러닝 모델 구축 및 분석 본문
머신러닝: 결정 트리와 앙상블 방법 쉽게 이해하기
1. 지도 학습 - 분류
분류(Classification)는 컴퓨터가 주어진 데이터를 보고 이 데이터가 어떤 종류(클래스)인지 예측하는 것을 말해요.
예를 들어, 사진을 보고 고양이인지 강아지인지 맞추는 것이 분류의 한 예입니다.
분류를 위해 사용하는 알고리즘(방법)에는 여러 가지가 있어요.
대표적인 분류 알고리즘
- 나이브 베이즈(Naive Bayes): 통계를 사용해 데이터를 분류하는 방법입니다. 예를 들어, 이메일이 스팸인지 아닌지를 확률로 예측할 수 있습니다.
- 로지스틱 회귀(Logistic Regression): 독립변수(설명 변수)와 종속변수(결과 변수) 간의 선형 관계를 이용해 데이터를 예측합니다.
- 결정 트리(Decision Tree): 나무처럼 생긴 구조로 데이터를 여러 단계의 질문을 통해 분류합니다.
- 서포트 벡터 머신(Support Vector Machine): 데이터를 분류할 수 있는 최적의 경계를 찾아주는 방법입니다.
- 최소 근접(Nearest Neighbor): 새로운 데이터 포인트가 주어졌을 때 가장 가까운 기존 데이터 포인트를 기준으로 분류합니다.
- 신경망(Neural Network): 뇌의 뉴런처럼 작동하는 네트워크를 사용해 데이터를 학습하고 예측합니다.
- 앙상블(Ensemble): 여러 가지 알고리즘을 합쳐서 더 정확한 예측을 합니다.
2. 결정 트리(Decision Tree) 모델
2.1 데이터 준비 및 학습
결정 트리는 나무 형태의 구조를 사용해 데이터를 분류하는 알고리즘이다.
이 알고리즘은 루트 노드에서 시작하여 각 노드에서 질문을 던지고, 이 질문에 따라 데이터를 나누어 간다.
이를 통해 최종적으로 각 데이터가 속할 클래스를 결정한다.
creditset2.csv 데이터를 이용해 DecisionTreeClassifier를 사용해 모델을 학습시킨다.
우선, 데이터를 학습 데이터와 테스트 데이터로 분리한 후, 결정 트리 모델을 생성하고 학습시킨다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
# 데이터 불러오기
credit = pd.read_csv("creditset2.csv")
# 7:3 비율로 train, test 데이터 분리
train, test = train_test_split(credit, test_size=0.3)
# Decision Tree 모델 생성 및 학습
dt = DecisionTreeClassifier()
dt.fit(train[["income","loan","age"]], train["default10yr"])
# 테스트 데이터로 예측
pred = dt.predict(test[["income","loan","age"]])
# 모델 성능 평가
print(classification_report(test["default10yr"], pred))설명:
- creditset2.csv 데이터를 불러와서 train과 test로 7:3 비율로 나눕니다.
- Decision Tree 모델을 생성하고, income, loan, age 피처를 이용해 학습시킵니다.
- 학습된 모델을 이용해 테스트 데이터를 예측합니다.
- 예측 결과를 평가(classification_report)하여 정확도(accuracy), 정밀도(precision), 재현율(recall), F1-score를 확인합니다.
2.2 모델 평가
모델 평가를 위해 학습된 모델을 사용하여 테스트 데이터를 예측하고, 그 결과를 classification_report를 통해 평가한다.
이때, 모델의 정확도, 정밀도, 재현율, F1-score와 같은 평가 지표를 확인할 수 있다.
위의 결과에서 볼 수 있듯이, 모델은 테스트 데이터에 대해 높은 정확도를 보여준다.
정확도는 전체 테스트 데이터 중 올바르게 분류된 데이터의 비율을 나타낸다.

# 전체 데이터셋으로 모델의 학습 성능 평가
dt.score(credit[["income","loan","age"]], credit["default10yr"])
# 피처 중요도 확인
dt.feature_importances_
# 테스트 데이터에 대한 예측 정확도 계산
np.mean(test["default10yr"] == pred)
설명:
- 모델의 학습 성능 평가:
- 이 코드는 학습된 Decision Tree 모델의 성능을 전체 credit 데이터셋에 대해 평가합니다.
- score 메서드는 기본적으로 정확도(accuracy)를 반환합니다. 이는 전체 데이터셋에서 모델이 올바르게 예측한 비율을 의미합니다.
2.3 피처 중요도 분석
결정 트리 모델은 각 피처의 중요도를 반환한다.
피처 중요도는 모델이 예측을 위해 각 피처를 얼마나 많이 사용했는지를 나타낸다.
피처의 중요도는 0과 1 사이의 값으로 표시되며, 값이 클수록 해당 피처가 모델에서 중요한 역할을 한다.
- 피처 중요도 확인:

- 이 코드는 학습된 모델에서 각 피처의 중요도를 반환합니다.
- 피처 중요도는 모델이 예측을 위해 각 피처를 얼마나 많이 사용했는지를 나타내며, 값이 클수록 해당 피처가 더 중요하다는 것을 의미합니다.S
- array([0.24984164, 0.47119223, 0.27896613])는 각 피처의 중요도를 나타내는 배열로, 순서대로 income, loan, age의 중요도를 나타냅니다.
- 테스트 데이터에 대한 예측 정확도 계산:

- 이 코드는 테스트 데이터에 대한 예측의 정확도를 계산합니다.
- test["default10yr"] == pred는 테스트 데이터의 실제 값과 예측 값이 일치하는지를 확인하여 Boolean 배열을 생성합니다.
- np.mean은 이 Boolean 배열의 평균을 계산하여, 예측이 일치하는 비율(정확도)을 반환합니다.
3. 앙상블 기법 - Random Forest
3.1 Random Forest 모델 학습 및 평가
앙상블 기법의 일종인 랜덤 포레스트는 여러 개의 결정 트리를 결합하여 예측 성능을 향상시키는 모델이다.
이 방법은 데이터를 여러 번 샘플링하여 각각의 샘플에 대해 여러 개의 결정 트리를 학습시킨 다음,
그 결과를 결합하여 최종 예측을 수행한다.
binary.csv 데이터셋을 이용해 DecisionTreeClassifier와 RandomForestClassifier를 비교한다.
# binary 데이터셋 불러오기
binary = pd.read_csv("binary.csv")
target = "admit"
# 7:3 비율로 train, test 데이터 분리
train, test = train_test_split(binary, test_size=0.3)
# Decision Tree 모델 생성 및 학습
dt = DecisionTreeClassifier()
dt.fit(train.drop(target, axis=1), train[target])
# 테스트 데이터로 예측
pred = dt.predict(test.drop(target, axis=1))
print(classification_report(test[target], pred))
# Random Forest 모델 생성 및 학습
rf = RandomForestClassifier()
rf.fit(train.drop(target, axis=1), train[target])
# 테스트 데이터로 예측
pred_rf = rf.predict(test.drop(target, axis=1))
print(classification_report(test[target], pred_rf))
설명:
- binary.csv 데이터를 불러와서 train과 test로 7:3 비율로 나눕니다.
- Decision Tree 모델을 생성하고 학습시킵니다.
- 학습된 모델로 테스트 데이터를 예측하고 성능을 평가합니다.
- Random Forest 모델을 생성하고 학습시킵니다.
- Random Forest 모델로 테스트 데이터를 예측하고 성능을 평가합니다.
3. Mortgage Default 데이터셋으로 Random Forest 실습
마지막으로 mortDefault2008.csv 데이터를 이용해 Random Forest 모델을 학습시키고 예측을 수행합니다.
# Mortgage Default 데이터 불러오기
mdf = pd.read_csv("mortDefault2008.csv")
mdf.drop("year", axis=1, inplace=True)
target = "default"
# 7:3 비율로 train, test 데이터 분리
train, test = train_test_split(mdf, test_size=0.3, random_state=1)
# Random Forest 모델 생성 및 학습
rf = RandomForestClassifier(n_estimators=10, max_depth=3)
rf.fit(train.drop(target, axis=1), train[target])
# 테스트 데이터로 예측
pred = rf.predict(test.drop(target, axis=1))
print(classification_report(test[target], pred))설명:
- mortDefault2008.csv 데이터를 불러와서 year 컬럼을 제거합니다.
- train과 test 데이터를 7:3 비율로 나눕니다.
- Random Forest 모델을 생성하고 학습시킵니다. (이때, 10개의 결정 트리를 사용하고 최대 깊이는 3으로 설정합니다.)
- 학습된 모델로 테스트 데이터를 예측하고 성능을 평가합니다.
결론
이번 포스팅에서는 Decision Tree와 Random Forest 알고리즘을 이용해 여러 데이터셋에 대해 모델을 학습시키고 예측을 수행한 후 성능을 비교해 보았습니다.
이를 통해 각 알고리즘의 장단점을 이해하고, 데이터 특성에 맞는 적절한 알고리즘을 선택하는 데 도움을 받을 수 있습니다.
4. 결정 트리와 앙상블의 시각적 이해
결정 트리의 구조는 루트 노드, 규칙 노드, 리프 노드로 구성되며, 각 노드는 데이터의 특정 피처에 대해 질문을 던지고, 이 질문의 결과에 따라 데이터를 분할한다.
결정 트리의 가지치기(Pruning)는 트리의 과적합을 방지하기 위해 노드를 제거하거나 병합하는 과정이다.
이를 통해 모델의 일반화 성능을 향상시킬 수 있다.

- 날개가 있나요?
- 날 수 있나요?
- 지느러미가 있나요?
이러한 질문을 통해 매, 펭귄, 돌고래, 곰 등을 분류할 수 있습니다.
장점:
- 사용하기 쉽고 이해하기 쉬워요.
- 데이터 전처리가 많이 필요 없어요.
단점:
- 너무 복잡한 트리는 과적합(overfitting) 문제를 일으킬 수 있어요. 즉, 너무 자세히 데이터를 분류하다 보니 새로운 데이터를 잘 못 맞출 수 있어요.

결정 트리의 구조
결정 트리는 루트 노드, 규칙 노드, 리프 노드로 구성됩니다.
- 루트 노드: 첫 번째 질문이 있는 곳
- 규칙 노드: 다음 질문이 있는 곳
- 리프 노드: 최종 답이 있는 곳
가지치기(Pruning)
가지치기는 너무 복잡해진 트리를 간단하게 만드는 과정입니다.
이렇게 하면 트리가 과적합되는 것을 막을 수 있습니다.
결정 트리(Decision Tree)의 주요 개념 - 데이터의 균일도

불순도(Impurity)
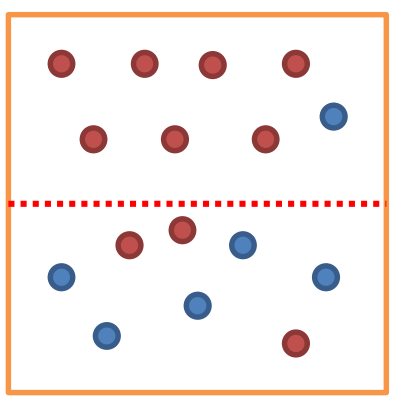
불순도는 데이터가 얼마나 섞여 있는지를 나타내요.
예를 들어, 빨간색과 파란색 공이 섞여 있을 때, 불순도가 높다고 할 수 있어요.
결정 트리는 불순도를 최소화하는 방향으로 학습해요.
5. 데이터 균일도와 엔트로피
데이터의 균일도를 나타내는 엔트로피와 지니 계수는 결정 트리에서 중요한 역할을 한다.
엔트로피는 데이터의 불순도를 나타내며, 값이 낮을수록 데이터가 균일하게 분포되어 있음을 의미한다.
반면, 지니 계수는 0에서 1 사이의 값을 가지며, 값이 낮을수록 데이터의 균일도가 높다.
엔트로피(Entropy)와 정보 이득(Information Gain)
- 엔트로피: 불순도의 척도. 엔트로피가 1이면 불순도가 최대, 0이면 최소. 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 의미합니다. 불순도가 낮을수록 데이터가 균일하게 섞여 있음을 의미합니다.
- 정보 이득: 엔트로피를 줄이는 정도. 엔트로피가 높은 속성을 기준으로 분할. 데이터를 나눠서 얼마나 순도가 높아졌는지를 나타냅니다. 엔트로피와 지니 지수가 주로 사용됩니다. 엔트로피가 낮아지면 정보 이득이 커집니다.
지니 계수(Gini Index)
불평등 지수를 나타내는 계수로, 0이 가장 평등하고 1로 갈수록 불평등해져요.
지니 계수가 낮을수록 데이터 균일도가 높아요.
결정 트리의 하이퍼파라미터
- max_depth: 트리의 최대 깊이.
- max_features: 최적의 분할을 위해 고려할 최대 피쳐 개수.
- min_samples_split: 노드를 분할하기 위한 최소 샘플 수.
- min_samples_leaf: 말단 노드가 되기 위한 최소 샘플 수.
- max_leaf_nodes: 말단 노드의 최대 개수.
6. 앙상블 기법: 배깅과 부스팅
앙상블 기법은 여러 개의 모델을 결합하여 예측 성능을 향상시키는 방법이다.
배깅(Bagging)은 데이터 샘플링을 통해 여러 모델을 학습시키고, 그 결과를 평균내어 최종 예측을 수행한다.
반면, 부스팅(Boosting)은 이전 모델의 오류를 보완하는 방향으로 새로운 모델을 추가하여 학습한다.
배깅(Bagging)
배깅은 데이터를 여러 번 복원 추출해서 각각의 트리들이 조금씩 다른 데이터를 사용하도록 하는 방법입니다.
이렇게 하면 모델이 더 튼튼해집니다.
데이터를 여러 번 복원 추출해서 여러 모델을 학습시킨 후, 그 결과를 평균내는 방법이에요
- 예) 랜덤 포레스트(Random Forest)
랜덤 포레스트는 여러 개의 결정 트리를 모아 만든 앙상블 모델입니다.
각 트리는 조금씩 다른 데이터를 사용해 학습합니다. 이렇게 하면 예측이 더 정확해지고 안정적이게 됩니다.
부스팅(Boosting)
이전 모델의 오류를 보완해가며 새로운 모델을 계속 추가하는 방법이에요. 예: Gradient Boosting, AdaBoost.
7. 실습 예제: 결정 트리와 Random Forest 비교
다양한 데이터셋을 활용하여 결정 트리와 랜덤 포레스트 모델을 학습시키고, 그 성능을 비교 분석한다.
각 데이터셋에 대해 모델의 학습 결과를 분석하고, 데이터 특성에 따라 어떤 모델이 더 적합한지 평가한다.
결정 트리 모델 학습
아래 코드는 결정 트리 모델을 학습시키고 시각화하는 예제입니다.



결론
이번 포스팅에서는 결정 트리와 앙상블 기법을 사용해 다양한 데이터셋에서 모델을 학습하고 예측 성능을 평가하였다.
이를 통해 각 알고리즘의 장단점을 이해하고, 데이터 특성에 맞는 적절한 알고리즘을 선택하는 방법을 배웠다.
이러한 기법들을 활용하여 머신러닝 모델을 더 효과적으로 개발할 수 있다.
'etc' 카테고리의 다른 글
| 금융공학8: 결정 트리와 앙상블 기법을 활용한 머신러닝 모델 비교와 실습 (0) | 2024.08.19 |
|---|---|
| 금융공학7: RNN과 LSTM을 활용한 시계열 데이터 예측 실습 (0) | 2024.08.18 |
| 금융공학6: ANN 기초부터 TensorFlow를 활용한 심층 신경망 구현까지 (0) | 2024.08.17 |
| 금융공학5: 리스크 관리와 포트폴리오 최적화: 데이터 분석과 CAPM 모델 활용 (0) | 2024.08.16 |
| 금융공학4: 군집 분석, 주성분 분석 (0) | 2024.08.15 |



